Estratificación socioeconómica: Un enfoque individual para una población de usuarios del transporte urbano en Chiclayo
Socioeconomic stratification: An individual Approach for an Urban Transportation User Population in Chiclayo
José Kayser Siesquén Díaz
Universidad Nacional Pedro Ruiz Gallo
Email: jsiesquendi@unprg.edu.pe
ORCID: https://orcid.org/0009-0009-0738-6691
Recibido: 28/03/2025
Aprobado: 04/06/2025
Publicado: 05/06/2025
Cómo citar este trabajo:
Siesquén Díaz, J.K. (2025). Estratificación socioeconómica: Un enfoque individual para una población de usuarios del transporte urbano en Chiclayo. Revista Reflexiones De La Sociedad Y Economía, 2(1), 156-195. https://doi.org/10.62776/rse.v2i1.47
![]()
© El autor. Este artículo es publicado por la Revista Reflexiones de la sociedad y economía de la Universidad Nacional Pedro Ruiz Gallo en Lambayeque, Perú, como acceso abierto bajo los términos de la Licencia Creative Commons Atribución 4.0 Internacional (https://creativecommons.org/licenses/by/4.0/). Esta licencia permite compartir (copiar y redistribuir el material en cualquier medio o formato) y adaptar (remezclar, transformar y construir a partir del material) el contenido para cualquier propósito, incluido el uso comercial.
![]()
Hasta ahora, no se ha investigado sobre la estratificación socioeconómica individual en el contexto del transporte urbano de la ciudad de Chiclayo, en Perú. Por lo tanto, este trabajo se centró en desarrollar una medida de ello para una población específica de usuarios del transporte en esta urbe, empleando parte de la información que facilitaron en 2019 al haber respondido un cuestionario socioeconómico de diseño propio. Tanto en el pilotaje como en la etapa oficial, se evaluó la validez y fiabilidad de siete indicadores clave previamente escogidos, pero solo oficialmente se logró su validación confirmatoria, mediante un modelado de ecuaciones estructurales basado en covarianzas (MEE-BC). Concluida esta evaluación, se calcularon dos índices socioeconómicos: uno tipificando las puntuaciones estimadas de dicho MEE-BC y otro estandarizando la suma de puntajes de los anteriores reactivos, por cuya sencillez y eficiencia se eligió y clasificó en cinco niveles socioeconómicos (al aplicar los quintiles de sus valores únicos). Los resultados definitivos revelaron que un 37.3% de los usuarios analizados pertenecía a un estrato bajo superior, seguido por aquellos situados en los segmentos medio (27.9%), alto (14.1%), bajo inferior (14.1%) y marginal (6.5%). No obstante, algunos en esta última categoría habrían estado integrando familias mejor posicionadas, y viceversa para una parte de quienes individualmente eran de una clase alta. De ahí que, aplicar un enfoque individual de estratificación socioeconómica, como el de este estudio, podría permitir la identificación de intervenciones más efectivas, contribuyendo así al desarrollo de la infraestructura y movilidad urbana en la región Lambayeque.
Palabras clave: Usuario del transporte urbano, análisis factorial exploratorio (AFE), MEE-BC, fiabilidad, nivel socioeconómico individual.
ABSTRACT
Until now, there has been no research on individual socioeconomic stratification in the context of urban transport in the city of Chiclayo, Peru. Therefore, this work focused on developing a measure for a specific population of transport users in this city, using part of the information they provided in 2019 when responding to a self-designed socioeconomic questionnaire. Both in the pilot phase and the official stage, the validity and reliability of seven key preselected indicators were evaluated, but confirmatory validation was only achieved officially through covariance-based structural equation modeling (CB-SEM). Upon concluding this evaluation, two socioeconomic indices were calculated: one typifying the estimated scores of the CB-SEM, and another standardizing the sum of scores of the previous items. The simplicity and efficiency of the latter led to its choice and classification into five socioeconomic levels (applying the quintiles of their unique values). The final results revealed that 37.3% of the analyzed users belonged to an upper-low stratum, followed by those in the middle (27.9%), high (14.1%), lower-low (14.1%), and marginal (6.5%) segments. However, some in the latter category might have been part of better-positioned families, and vice versa for some who were individually from a high class. Thus, applying an individual socioeconomic stratification approach, as in this study, could allow for the identification of more effective interventions, thereby contributing to the development of infrastructure and urban mobility in the Lambayeque region.
Keywords: Urban transportation user, exploratory factor analysis (EFA), CB-SEM, reliability, individual socioeconomic level.
INTRODUCCIÓN
El estatus o nivel socioeconómico, un concepto clave y complejo para especialistas de la salud, economía, educación y otras ciencias sociales, refleja una realidad desafiante para millones de familias, afectando su calidad de vida (Ware, 2017). Entre los integrantes de cualquier sociedad existen diferencias socioeconómicas en aspectos como la educación, los ingresos, el prestigio, el trabajo u otros (McLeod y Nonnemaker, 1999; L. Rodríguez et al., 2020), los cuales influyen colectivamente en su posicionamiento social (Fotso y Kuate-Defo, 2005; Wicki, 2022). Es más, las marcadas diferenciaciones en los retornos laborales, reflejadas en un acceso desigual a los servicios, la atención médica y la educación (Acevedo-García y Lochner, 2003; Rumberger y Palardy, 2005; Wicki, 2022), junto a la segregación espacial y habitacional (Iceland et al., 2002; Taeuber y Taeuber, 2008), han hecho referencia a dos de los ejemplos ilustrativos más drásticos de disparidad socioeconómica (Hilman et al., 2022).
En el ámbito del transporte urbano, esto último ha implicado la accesibidad diferenciada a las opciones de transporte público y privado. Se ha probado que existen divergencias significativas en los hábitos de viaje entre distintos grupos socioeconómicos (Cao et al., 2019). A manera de ejemplo, se ha encontrado que es más asequible ver a aquellos con bajos ingresos hacer uso del transporte público, mientras que los más ricos tienen mayor probabilidad de viajar en vehículos privados (Garrett y Taylor, 1999). Naturalmente, la segregación socioeconómica afecta cómo las personas transitan por una urbe. Su ubicación en distintas clases socioeconómicas ha hecho menos habitual su encuentro de lo que potencialmente es permitido por la estructura de un área urbana (Dong et al., 2020; Moro et al., 2021; Netto et al., 2015).
Desde distintos enfoques, se ha abordado o demostrado un correlato entre la conducta humana en espacios geográficos específicos y la dinámica socioeconómica (Ariza y Solís, 2009; Azocar et al., 2008; Boterman y Musterd, 2016; Marston, 2000; Paasi, 2004; S. Rodríguez y Cabrera-Barona, 2024). Ante una mezcla homofílica (McPherson et al., 2001), aquellos con una realidad socioeconómica similar han frecuentado sitios afines e interactuado entre sí (A. Morales et al., 2019; Bora et al., 2014; Wang et al., 2018; Yip et al., 2016). Para Hilman et al. (2022), esto ha generado patrones estratificados de redes sociales y trayectos urbanos personales predecibles, los cuales podrían alterarse por el deseo de experiencias diversas.
Sumado a lo anterior, la variabilidad de rasgos socioeconómicos, como el grupo étnico, el nivel educativo, el sector ocupacional, entre otros, también afecta la movilidad dentro de los espacios urbanos mediante la segregación residencial (Browning et al., 2017; Desu, 2015; Iceland et al., 2002; Taeuber y Taeuber, 2008). Aquí, aquellos con antecedentes parecidos habitan cerca unos de otros, formando en las urbes áreas fragmentadas (Hilman et al., 2022). Aunque, cabe señalar que las movilizaciones diarias pueden reducir o amplificar los niveles de segregación obtenidos al incluir únicamente aspectos residenciales (Liao et al., 2024).
De ahí que, la estratificación socioeconómica es clave en la formulación de políticas públicas, orientadas a reducir desigualdades sociales y económicas mediante programas concretos (Zhou y Wodtke, 2019). Su análisis es crucial, ya que permite entender cómo las personas acceden a recursos, oportunidades y bienestar (Fotso y Kuate-Defo, 2005). Particularmente, su inclusión es fundamental para tener una idea clara de la movilidad urbana y poder delinear sistemas de transporte más equitativos. Pese a esto, es un tema polémico (Fujihara, 2020; Tang, 2017; Haer, 1957), pues operacionalizar indicadores válidos requiere integrar teorías y métodos adecuados (K. Morales et al., 2021). Empero, la principal traba al medir la estratificación social se ha dado en la diversidad y complejidad de las propuestas teóricas (Haug, 1977).
Al respecto, Ware (2017) indica que el concepto de estatus socioeconómico se ha visto relegado por décadas; y que la ausencia de una definición concertada se debe a la irrastreabilidad de sus raíces conceptuales en Marx y Engels (1964), Parsons (1940) y Weber (1946), aun al estar bien instituidos conceptos afines como clase social y estratificación social. A su vez, White (1982), Raudenbush y Willms (1995), Sirin (2005), van Ewijk y Sleegers (2010), Caro y Cortés (2012), Cowan et al. (2012), Dickinson y Adelson (2014), así como León y Collahua (2016), coinciden en que su definición única es compleja de obtener, debido a su carácter multidimensional y su estrecha relación con el entrono que busca evaluar o medir.
Pese a ello, el nivel socioeconómico suele tratarse de una jerarquía basada en el acceso desigual a recursos como riqueza y estatus social (Mueller y Parcel, 1981; Oakes y Rossi, 2003). Permite ordenar a las personas según sus rasgos económicos y sociales en un sistema jerarquizado (Caro y Cortés, 2012; León y Collahua, 2016; Mueller y Parcel, 1981). Incluso, para muchos ha sido una función del capital material, humano y social (Bradley y Corwyn, 2002; Entwisle y Astone, 1994; Oakes y Rossi, 2003). El primero contiene recursos tangibles, el segundo los de tipo no material, y el tercero se manifiesta en las relaciones interpersonales (Coleman, 1988), partiendo de su fuerza y efecto en el acceso a recursos, según Bourdieu (1986).
Además, Ware (2017) indica que, en conjunto, estas tres formas de capital resumen los recursos deseables-asequibles para una persona; pero que medir su acceso es complejo. También señala que el estatus socioeconómico, al ser un factor latente, solo puede estimarse de forma inexacta, con la justificación requerida, siendo adecuado usar varios ítems según los recursos disponibles y el fin de los datos. Si bien su medición ya era de gran interés en 1928 (Chapin, 1928), poco se ha avanzado en su precisión (Oakes y Rossi, 2003), pese a su extenso uso en diversas áreas, tanto para realizar predicciones (Fotso y Kuate-Defo, 2005; Fujihara, 2020) como para explicar resultados (Caro et al., 2009; Dickinson y Adelson, 2014; Ensminger et al., 2000; Erdem y Kaya, 2021; Ferrão, 2009; Malecki y Demaray, 2006; Naushad, 2022; Okoye y Okecha, 2008; Rumberger y Palardy, 2005; Ware, 2017; Weiser y Riggio, 2010).
De hecho, varios trabajos han revisado el concepto y/o medida del nivel socioeconómico y su relación con el desarrollo infantil (Bradley y Corwyn, 2002; Ensminger et al., 2000; Gottfried, 1985; Hauser, 1994), la desigualdad, el clima escolar y/o el rendimiento académico (Berkowitz et al., 2016; Campoverde, 2024; López et al., 2022; Velez et al., 1994); han llevado a cabo una revisión sobre lo referente a su estimación dentro del ámbito de la salud (Berkman y Macintyre, 1997; Braveman et al., 2005; Diemer et al., 2012; Gagné y Ghenadenik, 2017; Oakes y Rossi, 2003); o han facilitado algunas sugerencias, a fin de mejorar su medición en estudiantes, niños, adolescentes, jefes de familias o individuos (Cowan et al., 2012; Ensminger y Fothergill, 2014; Mueller y Parcel, 1981). Al respecto, Entwisle y Astone (1994) han ofrecido ciertas pautas para captar datos raciales/étnicos y socioeconómicos que permitan designar de manera más precisa a los jóvenes en grupos según estos rasgos. En cambio, Avvisati (2020) ha analizado la historia de la medición del estatus socioeconómico en el Programa para la Evaluación Internacional de Alumnos (PISA, por sus siglas en inglés) y ha detectado las bases teóricas del índice de estatus económico, social y cultural (ESCS, por sus siglas en inglés).
Más aún, diversos meta-análisis han relacionado el estatus socioeconómico con el rendimiento académico (Çiftçi y Cin, 2017; León y Collahua, 2016; Liu et al., 2022; Sirin, 2005; van Ewijk y Sleegers, 2010; White, 1982) o los signos depresivos (Korous et al., 2022). Además, Chapin (1928) planteó una escala cuantitativa, como primer intento de medir del nivel socioeconómico familiar. Otros estudios han utilizado o ajustado escalas estandarizadas para captar información de este factor latente (Naushad, 2022) o evaluarlo (Vera y Vera, 2013; Weiser y Riggio, 2010). En cambio, Long y Renbarger (2023) revisaron sistemáticamente la evolución de su medición desde que sus inicios, hallando que la educación, ocupación e ingresos de los padres han sido habitualmente sus tres grandes indicadores a lo largo del tiempo.
Aunque cabe señalar que, para 1980, variables como el valor y las características de la vivienda, el goce de becas, ayudas o libros en el hogar, u otras menos usuales, como viajar, tener servicio doméstico o la frecuencia de visitas al dentista, ya se usaban en el entorno anglosajón al estimar el estatus socioeconómico (White, 1982). A su vez, en los años noventa hubo un mayor empleo de indicadores referidos al equipamiento de los hogares (Sirin, 2005), mientras que durante la primera década de este siglo se han sumado más factores (Gill, 2011). De ahí que, las consultas diseñadas han sido sobre la propiedad de la vivienda, automóviles, computadoras o videojuegos (Weiser y Riggio, 2010); el lugar donde se labora y vive (Okoye y Okecha, 2008); la percepción sobre la ayuda estatal (Ensminger et al., 2000); el disfrute de libros y becas de comedor (Ferrão, 2009); o el acceso a comidas escolares gratuitas o las que han tenido un bajo costo (Ensminger et al., 2000; Malecki y Demaray, 2006; Weiser y Riggio, 2010).
Ya en lo operativo, para medir el nivel socioeconómico familiar se ha usado variables simples, como las antes señaladas, o se ha construido índices en base a ellas (Gill, 2011). Esto, al sumar sus puntajes (Weiser y Riggio, 2010) o al promediarlos (Ensminger et al., 2000), algunas veces ponderándolos con información proveniente del criterio de expertos (V. Rodríguez y Espinoza, 2015). También al estandarizar este valor esperado, luego de ponderarlo con datos captados de la literatura respectiva (Caro, 2002) o de aplicaciones preliminares del análisis de componentes principales (Ministerio de Educación [MINEDU], 2018). De hecho, esta técnica estadística ha sido otra de las vías empleadas, con el fin de reducir la dimensionalidad de los datos contenidos en dichos indicadores (Caro, 2002; Caro y Cortés, 2012; Fotso y Kuate-Defo, 2005; Gill, 2011; Naushad, 2022). Inclusive, se ha utilizado su versión no lineal (K. Morales et al., 2021) o junto con el método de asignación óptima (Cuellar et al., 2016).
Se han aplicado, de igual modo, otros métodos en la construcción de índices socioeconómicos. En lo particular, Fujihara (2020) hiso uso del análisis de regresión (donde los coeficientes que obtuvo le permitieron predecir valores de lo que llamó índice socioeconómico japonés). Por el contrario, con base en la teoría de respuesta al ítem (TRI), se ha utilizado el método bayesiano multinivel (May, 2006) o el modelo de Rasch (Haretche, 2011). Otra de las técnicas usadas ha sido el análisis de correspondencia múltiple y el de escalamiento óptimo (Artola y Blumethal, 2015). Además, se ha explorado la medición del nivel socioeconómico dentro del marco de las ecuaciones estructurales con múltiples indicadores y múltiples causas o MIMIC, por sus siglas en inglés (Dickinson y Adelson, 2014; Oakes y Rossi, 2003).
Tampoco se ha usado una sola técnica al distribuir estos índices. Por ejemplo, se han clasificado sus puntajes factoriales empleando medidas de tendencia central, como cuartiles (Gill, 2011) o quintiles (Caro, 2002). A su vez, Malecki y Demaray (2006) asignaron un estrato bajo o alto a su población objetivo si es que accedía a almuerzos gratuitos o de bajo costo. En cambio, Vera y Vera (2013) adaptaron al caso lambayecano el intervalo de puntuaciones que la Asociación Peruana de Empresas de Inteligencia de Mercados (APEIM) manejó entre los años 2008 y 2009 al clasificar a las familias peruanas, bien sea en un nivel socioeconómico alto (A), medio (B), bajo superior (C), bajo inferior (D) o marginal (E), dada su realidad.
Lo que no se ha encontrado son trabajos sobre la estratificación socioeconómica individual en el sector del transporte urbano de la región Lambayeque. Aunque Vera y Vera (2013) evaluaron el nivel socioeconómico en este contexto, su enfoque fue familiar, no abordando las diferencias individuales dentro de un hogar, lo cual es crucial dado que las decisiones de movilidad, como elegir entre transporte público o privado, dependen más de las condiciones personales. Lograr reconocer estas variaciones permitiría una planificación más precisa de los sistemas existentes de transporte urbano. Por tanto, en este estudio se ha propuesto desarrollar una medida del nivel socioeconómico, pero siguiendo un enfoque individual y para las personas que frecuentaron la avenida Francisco Bolognesi de la ciudad de Chiclayo en 2019.
METODOLOGÍA
Diseño y muestra
Se aplicó un estudio no experimental a un grupo específico de la demanda del transporte urbano (DTU) en la ciudad de Chiclayo. Exactamente, se trató de residentes estables en las provincias de Chiclayo, Lambayeque y Ferreñafe que recibían ingresos monetarios por su labor y viajaban regularmente por la avenida Francisco Bolognesi de dicha urbe (en transporte público o privado y por trabajo u ocio). Sin intervenir o manipular su entorno, el 2 de octubre y el 10 de noviembre de 2019 se recolectó de manera preliminar y oficial cierta información primaria sobre algunos aspectos significativos de su situación socioeconómico individual.
No obstante, dada su complejidad y el costo que se debía asumir, solo se encuestó a una muestra representativa de estas personas, elegida de forma aleatoria, estratificada y proporcional. Mejor dicho, su cálculo consistió en sumar las muestras de cada provincia, estimadas a partir de sus poblaciones proyectadas con base en las tasas de crecimiento promedio anual calculadas por el Instituto Nacional de Estadística e Informática (INEI, 2018, p. 24).
En cuanto al margen de error y el valor crítico de la distribución normal, estos fueron de .05 y 1.96 por caso (para un nivel de confianza del 95.0%). Además, la probabilidad de éxito fue la de tener la oportunidad de encuestar a alguien de la DTU objetivo.
Así, se obtuvo un total de 276 personas que contestaron el cuestionario socioeconómico (CSE) oficial, mientras que el número preliminar de encuestados representó el 25 % de esta cantidad. De hecho, el 77.2%, 17.4% y 5.4% de ambas muestras debían habitar, de forma respectiva, las provincias anteriormente mencionadas. Estos resultados, de cierta manera, se alineaban con las proyecciones poblacionales. Se esperaba que el 66.5%, 25.4% y 8.0% de la población total en la región Lambayeque residieran en esas áreas provinciales.
Algo que también se debe señalar sobre el número de observaciones estimadas es que superaba los 200 casos mínimos sugeridos por Ferrando y Anguiano-Carrasco (2010, p. 25) para evaluar la calidad de algún instrumento de medición, incluso en un escenario óptimo (i.e., con factores bien establecidos y comunalidades elevadas). Al sobrepasar este umbral se cumplía justamente con lo que Hadiuzzman et al. (2017) indicaban como necesario para analizar una determinada muestra mediante el modelado de ecuaciones estructurales (MEE).
Selección de indicadores
Por supuesto, hubo que reformular la mayoría de estas variables. El fin fue hacerlas más claras para los encuestados. A diferencia de Calmet y Capurro (2011), se abrevió la consulta sobre su situación laboral y los activos de su hogar. Junto a ello, se incluyó la tenencia de internet como una opción más de respuesta a esta última pregunta, igual a lo que hizo la APEIM (2019) como parte del reajuste de su fórmula del NSE. También, se añadieron más alternativas al ítem grado de estudios, tanto este como el material principal de los pisos de la vivienda se plantearon como proposiciones, y se omitieron palabras innecesarias al consultar sobre el lugar de atención ante problemas de salud, todo lo cual difería de lo que Vera y Vera (2013) mostraron al adaptar una escala en una población de Lambayeque para evaluar el NSE familiar.
La tabla 1 contiene las descripciones oficiales de estos siete indicadores. Al respecto, es preciso señalar que, inicialmente, la consulta fue cuánto era su ingreso mensual, pero solo un 7.2% de la DTU encuestada en el pilotaje comprendió la pregunta. Otro 81.2% indicó que pudo haberla entendido mejor con un lenguaje más sencillo y aclaraciones sobre si tal retorno era por trabajar todos los días laborables, dado que el 71.4% trabajaba informalmente. Por tales motivos, en la etapa oficial se preguntó directamente cuánto ganaban al mes (en soles).
De hecho, desde la fase piloto, esta pregunta buscó captar información cuantitativa-descriptiva. A diferencia de Vera y Vera (2013), no se consideró una escala de ingresos familiares, pues lo que se buscaba era una medición individual más precisa, relevante para una investigación más amplia del transporte urbano (más detalles en Siesquén y Cabrejos, 2024).
Tabla 1. Preguntas consideradas para el recojo de información sobre el nivel socioeconómico de la población objetivo de usuarios del transporte urbano en Chiclayo, año 2019.
|
Etiqueta original de la variable |
Explicación de la variable |
|
1. Nivel de estudios. |
1 = Sin estudios; 2 = Primaria incompleta; 3 = Primaria completa; 4 = Secundaria incompleta; 5 = Secundaria completa; 6 = Superior técnico incompleto; 7 = Superior técnico completo; 8 = Estudios universitarios incompletos; 9 = Estudios universitarios completos; 10 = Maestría completa; 11 = Doctorado completo. |
|
|
|
|
2. ¿Cuál es su condición laboral actual? |
1 = Ambulante (informal); 2 = Trabajador familiar; 3 = Trabajador independiente; 4 = Trabajador dependiente; 5 = Empleador. |
|
|
|
|
3. ¿Cuánto gana al mes? (en soles) |
Respuesta abierta. |
|
|
|
|
4. Tipo de vivienda. |
1 = Vivienda improvisada; 2 = Vivienda en callejón; 3 = Vivienda en quinta; 4 = Apartamento en edificio; 5 = Casa independiente. |
|
|
|
|
5. Material predominante en los pisos de su vivienda. |
1 = Tierra / Arena; 2 = Cemento sin pulir (falso piso); 3 = Cemento pulido / Tapizón; 4 = Mayólica / Losetas / Cerámicas; 5 = Parquet / Madera pulida / Alfombra / Mármol / Terrazo. |
|
|
|
|
6. En su hogar cuenta con: |
Cocina, refrigeradora, lavadora, internet, servicio doméstico, teléfono fijo. Respuesta múltiple (con 0 = no y 1 = sí para cada una de estas alternativas). |
|
|
|
|
7. ¿A dónde acude cuando tiene algún problema de salud? |
1 = Posta médica / Farmacia / Naturista; 2 = Hospital del Ministerio de Salud / Hospital de la Solidaridad; 3 = Seguro social / Hospital de las FFAA / Hospital de la policía; 4 = Médico particular en consultorio; 5 = Médico particular en clínica privada. |
Nota. Adaptado de Siesquén y Cabrejos (2024, p. 91). FFAA = Fuerzas Armadas. La numeración de los ítems difiere de la que tuvieron dentro del cuestionario socioeconómico de elaboración propia, el cual estuvo compuesto por más indicadores, a fin de poder captar cierta información con respecto al ámbito del transporte urbano. Para más detalles sobre esto, ver Siesquén y Cabrejos (2024, pp. 382-385).
El resto de los ítems se mantuvo sin cambios. Más bien, no se incluyó la consulta sobre el gasto mensual en distintos rubros que hizo Calmet y Capurro (2011) o las subescalas de hacinamiento usadas por Vera y Vera (2013). Esto, porque sus respuestas eran más indicadores de la situación social y económica desde una perspectiva familiar que personal.
Recolección, organización y análisis de la información
Figura 1. Esquematización del procedimiento aplicado en la medición del NSE individual para una muestra de usuarios del transporte urbano objeto de estudio en 2019.
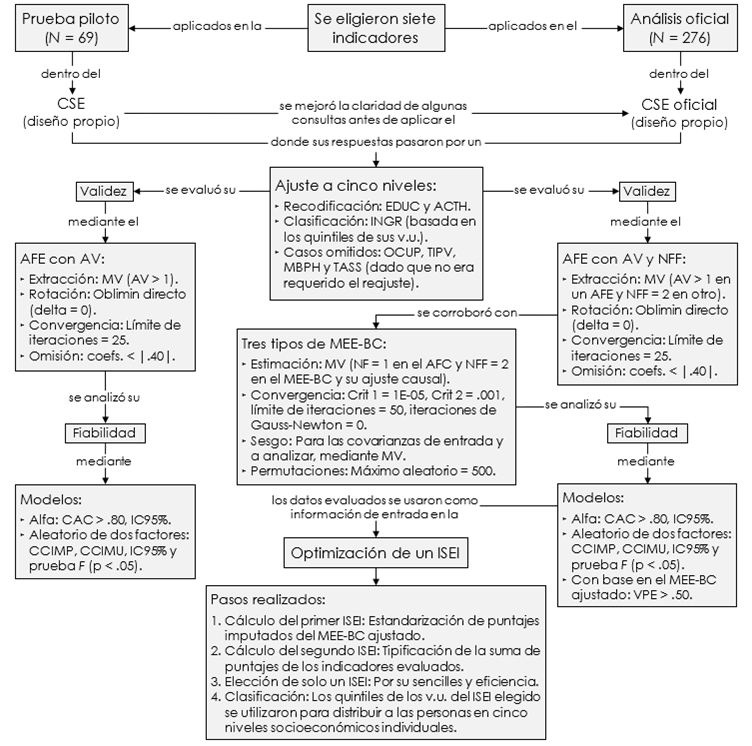
Nota. CSE = cuestionario socioeconómico; EDUC = nivel educativo; OCUP = condición laboral; ACTH = activos del hogar; NFF = número de factores fijos; MBPH = material base en el piso del hogar; TIPV = Tipo de vivienda; INGR = nivel de ingresos monetarios; TASS = tipo de acceso al servicio de salud; MV = máxima verosimilitud; AV = autovalores; VPE = varianza promedio extraída; coefs. = coeficientes; Crit = criterio; AFE = análisis factorial exploratorio; v.u. = valores únicos; AFC = análisis factorial confirmatorio; CCI = coeficiente de correlación intraclase; CCIMP = CCI para medidas promedio; CCIMU = CCI para medidas únicas; CAC = coeficiente alfa de Cronbach; ISEI = índice socioeconómico individual; MEE-BC = modelado de ecuaciones estructurales basado en covarianzas.
Una vez recabada la información requerida, en ambas fases se pasó a reagrupar en cinco niveles las respuestas sobre el nivel educativo (EDUC), respetando la escala inicial de sus alternativas. Quienes habían terminado su maestría o doctorado se ubicaron en el quinto nivel. Les siguieron aquellos que lograron completar su formación universitaria o técnico superior (cuarto nivel) o no (tercer nivel), y a estos los que culminaron o no la secundaria (segundo nivel) y las personas con primaria completa o trunca, o sin educación (primer nivel). Los activos del hogar (ACTH), según lo expuesto en la Figura 1, fue el otro ítem que enfrentó lo mismo, ya que ahora su quinta clase abarcó cinco o seis bienes o servicios, la cuarta cuatro de ellos, la tercera únicamente tres, y así hasta la primera, que estuvo reservada para solo un bien o servicio.
Por su parte, el indicador ingresos monetarios se agrupó en cinco clases, aplicando los quintiles salariales de sus cifras únicas. A partir de los conceptos matemáticos de multiconjunto (multiset o mset) y cuantil, la idea era sencilla: al disponer de un conjunto finito de remuneraciones w, solo se consideró cada salario único wu del mset (w, m), omitiendo su multiplicidad m > 0 (i.e., su frecuencia de aparición). Esto se hizo para mitigar el sesgo de estas repeticiones, facilitando así una visión más clara e imparcial de la distribución salarial analizada.
Acto seguido, se adaptó al caso de las quintillas el
cálculo del p-ésimo percentil explicado por Toma y Rubio (2017, p. 142).
Se ordenaron de menos a más los montos reportados y se estimó el ĸ-ésimo
valor de ƙ según esta posición y el número total de ingresos únicos (nwu) analizados.
De estos resultados, su parte entera (e) indicó la posición de las cifras
requeridas para calcular el ĸ-ésimo quintil salarial único (KSU),
mientras que la parte decimal (![]() ) se desempeñó
como un coeficiente de ajuste. Una notación más compacta del conjunto integrado
por cada wu y
las fórmulas utilizadas en la determinación del valor de ƙĸ y
la ĸ-ésima quintilla salarial anterior se especifican en las
ecuaciones 1, 2 y 3, siguiendo ese orden.
) se desempeñó
como un coeficiente de ajuste. Una notación más compacta del conjunto integrado
por cada wu y
las fórmulas utilizadas en la determinación del valor de ƙĸ y
la ĸ-ésima quintilla salarial anterior se especifican en las
ecuaciones 1, 2 y 3, siguiendo ese orden.
|
|
Supp(w) := {wu ∈ w*: mw(wu) > 0} |
(1) |
|
|
|
(2) |
|
|
KSUĸ = wue
+ |
(3) |
Donde Supp(w) enunciaba el soporte del mset (w, m) o el grupo de ingresos monetarios (tanto del pilotaje como oficiales) sin sus multiplicidades. A su vez, w* denotaba el universo salarial o todas las retribuciones posibles en este multiconjunto, cuya función de multiplicidad mw(wu) representaba el número de repeticiones de wu. Sumado a esto, es importante mencionar que el cálculo del ĸ-ésimo KSU se realizó para todo ĸ = 1, 2, … , 5.
Así, los quintiles de los 11 montos distintos detectados preliminarmente fueron 882, 1160, 1840 y 2680 soles. Ya oficialmente, de las 12 cifras diferentes identificadas se obtuvo los siguientes umbrales: 830, 1040, 1740 y 2620 soles, siendo los únicos que se tuvieron en cuenta debido al mayor rango salarial reportado en esta etapa (un monto mínimo de 400 soles y uno máximo de 4500 soles, frente a los 800 a 4500 soles en el pilotaje). Fue especialmente útil estimar quintillas a partir de este grupo menor de remuneraciones, dado que permitió identificar mejor los rangos salariales de la población de interés en la presente investigación. Con esto se terminó generando una nueva variable observable: el nivel de ingresos monetarios (INGR).
Por otro lado, no se recodificaron las respuestas sobre la condición laboral (OCUP), el tipo de acceso al servicio de salud (TASS), tipo de vivienda (TIPV) y material base en el piso del hogar (MBPH), proporcionadas por la DTU encuestada. Como lo indica la Figura 1, esto fue porque cumplían desde el inicio con tener cinco alternativas de carácter ordinal.
Validación exploratoria: Autovalores versus factores fijos.
Culminado
el ajuste de las respuestas a tres de los siete ítems elegidos, se evaluó si todos
ellos reflejaban adecuadamente el concepto de NSE bajo un enfoque individual. Para
ello, según lo sugerido por Lloret-Segura et al. (2014, p. 1159), se
inició verificando si era viable su análisis factorial, probando la
siguiente hipótesis nula: ![]() = 0 (con
= 0 (con ![]() siendo el
coeficiente de correlación bivariada entre estos reactivos), y viendo si el determinante
de la matriz de correlaciones tendía a cero. También se calculó el
índice de Kaiser-Meyer-Olkin (KMO), una medida de adecuación
muestral que permite evaluar cómo un grupo de variables observadas se asocian
conjuntamente al analizar el grado en el que pueden predecirse entre sí (López-Aguado
y Gutiérrez-Provecho, 2019, p. 7). Además, se aplicó la prueba de
esfericidad de Bartlett.
siendo el
coeficiente de correlación bivariada entre estos reactivos), y viendo si el determinante
de la matriz de correlaciones tendía a cero. También se calculó el
índice de Kaiser-Meyer-Olkin (KMO), una medida de adecuación
muestral que permite evaluar cómo un grupo de variables observadas se asocian
conjuntamente al analizar el grado en el que pueden predecirse entre sí (López-Aguado
y Gutiérrez-Provecho, 2019, p. 7). Además, se aplicó la prueba de
esfericidad de Bartlett.
El siguiente paso consistió en realizar un análisis factorial exploratorio (AFE) para detectar la cifra y estructura de los factores comunes que explican la varianza compartida por los reactivos evaluados (Lloret-Segura et al., 2014, p. 1152). Basándose en las explicaciones de Peña (2013, pp. 348-363), se propuso que el vector r de ítems, con formato 7 × 1, observados en la población objetivo, se derivaba mediante la relación indicada en la ecuación 4.
|
|
r = Λ×F + ϵ |
(4) |
Con F como vector de factores que explicaban la varianza común de los indicadores evaluados (de orden a × 1) y Λ siendo la matriz de cargas factoriales (de tamaño 7 × a). A la vez, ϵ era el vector, de dimensiones 7 × 1, que contenía el efecto en r de todas las variables no incluidas en F. Al no ser visibles, se asumió que los factores en F y ϵ seguían una distribución normal. Es más, se planteó que la matriz de covarianzas muestral podía ser aproximadamente la suma de dos matrices, cumpliendo la propiedad cardinal del modelo factorial.
En cuanto a la extracción factorial, se adoptaron las sugerencias de Lloret-Segura et al. (2014, pp. 1159-1160, 1166). Si bien ahora todas eran variables ordinales, cada una contaba con cinco clases de respuesta. Además, en la Tabla 2 se logra apreciar que solo el indicador ACTH parecía no seguir una distribución aproximadamente normal. Pero esto únicamente durante el pilotaje, pues su curtosis excedía en 0.107 el límite superior sugerido por Muthén y Kaplan (1985, 1992) y Bandalos y Finney (2019). Sin embargo, esta desviación no resultaba ser notoria y alarmante. De manera que, como lo muestra la Figura 1, el método de estimación que al final se aplicó de forma preliminar y oficial fue el de máxima verosimilitud (MV).
Otra recomendación de Lloret-Segura et al. (2014, pp. 1161-1163, 1166) que se consideró fue contrastar los resultados del ajuste de varios modelos. En este caso, se analizaron dos: uno con dos factores fijos y otro basado en autovalores mayores a la unidad (AV > 1), dada la falta de consenso sobre el modelado del estatus socioeconómico (ESE), pese a haber varias propuestas de ello (e.g., ver Dickinson y Adelson, 2014; Oakes y Rossi, 2003).
Tabla 2. Medidas estadísticas de forma en la distribución de respuestas a los indicadores del NSE individual para los usuarios del transporte urbano objeto de estudio en 2019.
|
Indicadores analizados |
Piloto: Asimetría |
Curtosis |
Fase oficial: Asimetría |
Curtosis |
|
Tipo de acceso al servicio de salud |
0.084 |
-0.946 |
0.204 |
-0.822 |
|
Nivel educativo |
-0.411 |
-0.219 |
-0.334 |
0.002 |
|
Condición laboral |
-0.447 |
-0.533 |
-0.298 |
-0.346 |
|
Nivel de ingresos monetarios |
0.081 |
-1.050 |
-0.005 |
-1.028 |
|
Tipo de vivienda |
-0.668 |
0.125 |
-0.855 |
0.517 |
|
Material base en el piso del hogar |
-0.829 |
-0.023 |
-0.983 |
0.600 |
|
Activos del hogar |
-1.829 |
2.107 |
-1.301 |
0.867 |
Nota. NSE = nivel socioeconómico. En cada caso, los errores estándar de asimetría y curtosis fueron de 0.289 y 0.570 en el pilotaje (N = 69), mientras que de 0.147 y 0.292 en la etapa definitiva (N = 276), respectivamente.
Finalmente, para facilitar la interpretación de la solución factorial obtenida, se decidió rotarla, asumiendo que los indicadores evaluados se encontraban influenciados por un grupo menor de factores. Siguiendo la directriz de Lloret-Segura et al. (2014, pp. 1163-1166), se usó un método de rotación oblicuo. En la Figura 1 se indica que puntualmente fue la siguiente técnica: Oblimin directo con normalización Kaiser, admitiendo en este caso un valor de delta = 0. El motivo de su selección se debió a las soluciones factoriales sencillas y comprensibles que frecuentemente producía bajo una buena convergencia (Lee y Jennrich, 1979).
Validación confirmatoria: Contraste de tres tipos de MEE-BC.
En su estudio, Hadiuzzman et al. (2017) sugerían que eran necesarias más de 200 observaciones para analizar una determinada muestra a través del MEE. Por tanto, como se indica en la Figura 1, solo los resultados del AFE en la fase oficial pasaron a corroborarse mediante el MEE basado en covarianzas (MEE-BC). Así, lo primero que se realizó fue un análisis factorial confirmatorio (AFC). Bajo este enfoque, cada ítem se asocia exclusivamente con el factor del que se considera un indicador válido, es permisible el contraste estadístico de hipótesis concretas, la correlación de componentes únicos, entre otros aspectos esenciales (Batista-Foguet et al., 2004, p. 24). De manera más específica, se planteó que todas las variables observables evaluadas se encontraban influenciadas por el constructo NSE. Partiendo de Bollen (1989, pp. 233-235, 306-311), en la ecuación 5 se indica la fórmula de este AFC de primer orden (AFC 1).
|
|
r = Λ×NSE + ϵ |
(5) |
Donde ahora Λ resumía los efectos directos del escalar NSE = [NSE] sobre los ítems acoplados en r. A su vez, ϵ agrupaba los errores de medida. Tanto r, ϵ y Λ eran vectores de orden 7 × 1. En un segundo AFC se asumió que cierto factor, llamado aspectos básicos (ASB), solo influía en los indicadores EDUC, OCUP, INGR y TASS, al mismo tiempo que otro, denominado nivel de habitabilidad de la vivienda (NHV), influenciaba únicamente en los reactivos TIPV, MBPH y ACTH. Además, ambos constructos dimensionaban el factor NSE. Este modelo estructural y los dos anteriores modelos de media se especifican en las ecuaciones 6 y 7 de forma respectiva, tomando como guía lo explicado por Bollen (1989, pp. 313-315).
|
|
F = Γ×NSE + ϛ |
(6) |
|
|
r = Λ×F + ϵ |
(7) |
|
Con F representando, en este caso, los constructos ASB y NHV, y Γ acoplando los efectos de NSE en estos dos factores, cuyos residuales se incluían en ϛ. Por ello, F, Γ y ϛ eran vectores de orden 2 × 1. Asimismo, Λ era ahora una matriz de cargas factoriales, de orden 7 × 2, con ciertas condiciones (e.g., pesos nulos de ASB y NHV en indicadores donde no se planteó su influencia, opuesto a lo manejado en el AFE). En cambio, r y ϵ seguían siendo vectores, de tamaño 7 × 1, que respectivamente abarcaban los ítems evaluados y sus residuos.
Sin embargo, este último AFC, uno de segundo orden (en adelante, AFC 2), fue reespecificado. En su versión ajustada (denominada AFC 3) se eliminó la dimensión ASB. De manera que los indicadores EDUC, OCUP, INGR y TASS, junto con el factor NHV, pasaron a verse afectados directamente por la variable latente NSE. Lo que si se siguió asumiendo fue la influencia directa del constructo NHV en los ítems TIPV, MBPH y ACTH. Basándose en Bollen (1989, pp. 319-338, 350-355), esta relación causal y el resto de modelos (tanto estructural como de medición) del AFC 3 se formulan en las ecuaciones 8, 9 y 10, en ese orden.
|
|
r(G1) = Λ(G1)×NHV + ϵ(G1) |
(8) |
|
|
NHV = Γ×NSE + ϛ |
(9) |
|
|
r(G2) = Λ(G2)×NSE + ϵ(G2) |
(10) |
Estando Λ(G1) integrada por los efectos del escalar NHV = [NHV] sobre los reactivos incluidos en r(G1), con los errores de medida respectivos constituyendo ϵ(G1), siendo todos estos vectores de dimensiones 3 × 1. De forma similar, ϵ(G2) acoplaba los residuos de los ítems contenidos en r(G2), mientras que Λ(G2) estaba compuesto por los efectos del parámetro NSE en estas variables observables, cada uno de ellos de orden 4 × 1. A su vez, Γ = [Γ] y ϛ = [ϛ] reflejaban la influencia de NSE sobre NHV y, de modo correspondiente, su error residual.
Como se muestra en la Figura 1, el método de MV se usó al estimar los tres tipos de MEE-BC previamente especificados y al manejar el sesgo en las covarianzas de entrada y a evaluar. Los criterios de convergencia fueron 0.00001 y 0.001, con un máximo de 50 iteraciones (ninguna de Gauss-Newton) y 500 permutaciones al azar. El fin fue asegurar la robustez de los hallazgos. Además, en el AFC 1 y AFC 3, el constructo NSE escalo en el ítem EDUC, y en ASB al tratarse del AFC 2. En este último AFC la escala de ASB también se determinó en el indicador EDUC, y la del factor NHV en el reactivo TIPV (igual que en el AFC 3).
Asimismo, los residuales en cada modelo se normalizaron a un valor de uno, definiéndose sus escalas según sus respectivos indicadores. A la vez, se asumió que la matriz de covarianzas del factor NSE o de ASB y NHV eran distintas a la de identidad, y que estos factores no covariaban con los residuos de los ítems evaluados (o exclusivamente con el residuo del constructo NHV, por parte del NSE, pues la ejecución del AFC 2 requirió que el constructo ASB no tuviera un error de medida, lo cual sugería una posible invalidez convergente).
Para mejorar la adecuación del AFC 1, AFC 2 y AFC 3, se precisó que covariaran los residuales de INGR y OCUP, e igual para los ítems TIPV y MBPH. Solo en el AFC 1, se requirieron dos covariaciones más: entre los residuos de ACTH y de los reactivos anteriores, respectivamente. Cada reajuste sugería la posible existencia de un patrón subyacente de variabilidad compartida no capturado completamente por el modelo de ecuaciones estructurales empleado (Raykov y Marcoulides, 2006; Kline, 2016). Esto probablemente se debió a la naturaleza de las variables anteriormente mencionadas y al concepto que intentaban representar.
Uno o más de dichos indicadores se han utilizado en diversos estudios para comunicar sobre el NSE de las familias (e.g., ver Artola y Blumethal, 2015; Caro, 2002; Caro et al., 2009; Caro y Cortés, 2012; Dickinson y Adelson, 2014; Ensminger et al., 2000; Ferrão, 2009; Fotso y Kuate-Defo, 2005; Gill, 2011; Haretche, 2011; May, 2006; MINEDU, 2018; K. Morales et al., 2021; V. Rodríguez y Espinoza, 2015; Vera y Vera, 2013; Weiser y Riggio, 2010). Pero, también han sido usados para exponer su situación en el mercado laboral (Becker, 1964) o nivel de pobreza no monetaria (Feres y Mancero, 2001; Villatoro, 2017), lo que puede haber explicado los casos ya mencionados de covariaciones entre errores de medición.
Cabe señalar que, para evaluar la adecuación del AFC 1, AFC 2 y AFC 3, se calculó el índice chi cuadrado (χ2, cuyo valor p mayor a .05 indica un buen ajuste del modelo a los datos) y la relación χ2/gl. Otro índice usado fue el error cuadrático medio de aproximación (RMSEA, por sus siglas en inglés), que mide la varianza que el modelo no explica por cada grado de libertad, aconsejándose un valor de 0.05 o menos, con un IC90% [0, 0.05], para un buen ajuste (Herrero, 2010). Pese a ello, Browne y Cudeck (1992) lo preferían menor a 0.08.
Además, se empleó el índice de ajuste comparativo (CFI, por sus siglas en inglés), desarrollado por Bentler (1990), cuyo valor en torno a .95 indica un ajuste adecuado, según Herrero (2010). El índice de ajuste de bondad (GFI, por sus siglas en inglés) también fue tomado en cuenta. De igual forma, se utilizó tanto el índice de parsimonia (PRATIO) como el criterio de información de Akaike (AIC), a fin de detectar el MEE-BC más parsimonioso.
Fiabilidad.
De acuerdo con la sugerencia hecha por Batista-Foguet et al. (2004, p. 24), una vez validados, se diagnosticó la fiabilidad de los indicadores EDUC, OCUP, INGR, TIPV, MBPH, ACTH y TASS. Para ello, la Figura 1 muestra que en el pilotaje y oficialmente se emplearon los modelos alfa y aleatorio de dos factores. Con el primer modelo se calculó el coeficiente alfa de Cronbach (CAC para abreviar), cuyo valor advertía de una fiabilidad inaceptable, pobre, débil, aceptable, buena u óptima si, de forma respectiva, no era menor a .50, se hallaba entre .50 y .60, .60 y .70, .70 y .80, .80 y .90 o excedía este último umbral (George y Mallery, 2010). A su vez, el segundo modelo permitió obtener el coeficiente de correlación intraclase para medidas únicas (CCIMU) y promedio (CCIMP), además de sus debidos intervalos de confianza al 95.0% y los resultados de una prueba F, con el fin de evaluar la significancia estadística de lo fiable que eran los ítems abordados (considerando los grados de libertad correspondientes). Ya que el CAC resultó ser equivalente al CCIMP, solo se consideró el IC95% de este último.
En la Figura 1 también se indica que, aprovechando los resultados derivados del MEE-BC más parsimonioso (que para ese entonces se sabía que era el AFC 3), se evaluó de forma más robusta la confiabilidad de los datos en la fase oficial, mediante el calculó de la varianza media extraída (VME). En un inicio, Fornell y Larcker (1981) propusieron este índice como una evidencia de validez convergente. Pero, lo que permite es relacionar la proporción de varianza explicada por un factor específico en contraste con la varianza total atribuible a su error de medición (Cheung y Wang, 2017), advirtiendo del nivel de precisión de un instrumento para medir un determinado constructo. La literatura señala que un valor de la VME se considera adecuado cuando es mayor a .50 (Baharum et al., 2023; Fornell y Larcker, 1981), sugiriendo que el factor evaluado explica más de la mitad de la varianza en sus ítems (Baharum et al., 2023).
Optimización del índice socioeconómico individual.
Concluida la evaluación intrínseca de su calidad, los siete reactivos anteriores se utilizaron en el cálculo de dos índices socioeconómicos individuales. Particularmente, para estimar el primer índice socioeconómico (ISE) de cada usuario, se tipificó el puntaje de su NSE (bajo un enfoque individual), el cual fue imputado a partir del MEE-BC más parsimonioso y que mejor se ajustó a los datos. En cambio, el segundo ISE individual se obtuvo al sumar directamente los puntajes de las repuestas a dichos reactivos y luego estandarizar el resultado. En efecto, esto reflejó dos enfoques distintos: uno basado en un modelo estadístico complejo (el más adecuado posible) y otro en una simple adición de puntuaciones previamente evaluadas.
Posteriormente, se evaluó la consistencia, eficiencia, robustez y posibles discrepancias de estas medidas socioeconómicas individuales. Esto se realizó a través de la prueba de correlación de Spearman y la de rangos de signos de Wilcoxon (incluidos sus respectivos tamaños del efecto y potencias estadísticas post hoc), debido a que ambos índices presentaban una distribución no paramétrica según la prueba de normalidad de Kolmogorov-Smirnov (primer ISE individual: D = 0.084, p < .001; segundo ISE individual: D = 0.087, p < .001).
Al final, se optó por el ISE individual más simple y
eficiente a la vez, el cual pasó a clasificarse en cinco niveles, siguiendo el
mismo método usado para la variable INGR. De modo que, solo se escogió cada
valor único de este ISE (iseu
en adelante), con el fin de mitigar el sesgo causado por sus repeticiones y,
así, ofrecer una perspectiva más precisa y equilibrada de la distribución y
diversidad socioeconómica de la población investigada. Luego, estos valores
distintos fueron ordenados ascendentemente y se estimó el ĸ-ésimo valor
de ƙ, en base a su posición y el número analizado de medidas únicas
(denotado por niseu).
De este resultado, la parte entera e indicó la posición concreta de
ciertos índices socioeconómicos únicos requeridos, mientras que la parte
decimal ![]() funcionó como
coeficiente de ajuste, sirviendo esto en el cálculo del ĸ-ésimo
quintil socioeconómico único (KSEU). En la ecuación 11 se muestra una notación
más compacta del conjunto formado por cada iseu.
Por su parte, las fórmulas empleadas en el cálculo del valor de ƙĸ
y KSEUĸ se especifican en las respectivas ecuaciones 12 y 13.
funcionó como
coeficiente de ajuste, sirviendo esto en el cálculo del ĸ-ésimo
quintil socioeconómico único (KSEU). En la ecuación 11 se muestra una notación
más compacta del conjunto formado por cada iseu.
Por su parte, las fórmulas empleadas en el cálculo del valor de ƙĸ
y KSEUĸ se especifican en las respectivas ecuaciones 12 y 13.
|
|
Supp(ISE) := {iseu ∈ ISE*: mISE(iseu) > 0} |
(11) |
|
|
|
(12) |
|
|
KSEUĸ = iseue + |
(13) |
Con Supp(ISE) y mISE(iseu) siendo el soporte y la función de multiplicidad del mset (ISE, m). Mientras tanto, ISE* representaba el universo de índices socioeconómicos individuales. Sobre el ĸ-ésimo KSEU, su estimación se dio para todo ĸ = 1, 2, … , 5.
Cada estrato planteado se basó en el trabajo realizado por Vera y Vera (2013) en una población de Lambayeque, así como en las clasificaciones que manejaban la APEIM (2017, 2018, 2019) y el INEI (2019). Estos enfoques se adaptaron por dos razones: reflejar de manera más precisa la realidad socioeconómica de la población investigada (i.e., los usuarios del transporte urbano que frecuentaron la avenida Francisco Bolognesi de la ciudad de Chiclayo en 2019) y poder contrastarla con los hallazgos de estudios que, a pesar de no haber realizado una estratificación socioeconómica individual, eran un referente útil para el análisis.
Además, se optimizó un índice de habitabilidad de la vivienda (IHV), pero solo para efectos de contraste. Se procedió igual que con el ISE individual, aclarando que únicamente se usaron los ítems TIPV, MBPH y ACTH (basándose en su valides). Aquí también se evaluaron dos índices con ayuda de los anteriores test no paramétricos, dado que sus distribuciones eran no normales (primer IHV: D = 0.104, p < .001; segundo IHV: D = 0.207, p < .001).
RESULTADOS Y DISCUSIÓN
Rasgos socioeconómicos individuales clave de la muestra oficial
Históricamente, diversos estudios han señalado que el logro educativo del padre, su condición ocupacional e ingresos monetarios se han utilizado de manera consistente como los principales aspectos del ESE de las familias (Bradley y Corwyn, 2002; Caro y Cortés, 2012; Cowan et al., 2012; Ensminger y Fothergill, 2014; Entwisle y Astone, 1994; Gottfried, 1985; Hauser, 1994; Long y Renbarger, 2023; May, 2006; Mueller y Parcel, 1981; Oakes y Rossi, 2003; Sirin, 2005; White, 1982; Willms, 2002). Para este trabajo, sin embargo, se han empleado como indicadores clave del NSE individual, junto con cuatro ítems más: el tipo de vivienda, el material base del piso del hogar, sus activos y el tipo de acceso a atención médica.
Esto último difiere de ciertas investigaciones que, además de haber seguido un enfoque familiar de estratificación socioeconómica, no consideraron ninguna de las siete variables mencionadas anteriormente (e.g., ver Malecki y Demaray, 2006; Okoye y Okecha, 2008; Ware, 2017; Weiser y Riggio, 2010). Otros trabajos, por el contrario, no han tomado en cuenta la cobertura del jefe del hogar al servicio de salud (e.g., ver Caro, 2002; Caro y Cortés, 2012; Dickinson y Adelson, 2014; Gill, 2011; Haretche, 2011; K. Morales et al., 2021; MINEDU, 2018), su clase de empleo y las retribuciones monetarias que conseguía debido a ello (e.g., Caro, 2002; Caro et al., 2009; Ensminger et al., 2000; Ferrão, 2009; Haretche, 2011; K. Morales et al., 2021; MINEDU, 2018) o, al menos, alguno de estos dos últimos ítems (e.g., Artola y Blumethal, 2015; Caro y Cortés, 2012; Gill, 2011; V. Rodríguez y Espinoza, 2015; Vera y Vera, 2013).
Desde luego, existen muchas más variables que se han usado para estimar el NSE familiar. Tal es el caso del acceso a comidas escolares con un precio reducido o gratuitas (Ensminger et al., 2000; Malecki y Demaray, 2006; Weiser y Riggio, 2010), la percepción sobre la asistencia del Estado (Ensminger et al., 2000), el lugar de trabajo y residencia (Okoye y Okecha, 2008) o el goce de becas de comedor (Ferrão, 2009), de una vivienda, auto y videojuego (Weiser y Riggio, 2010), libros (Ferrão, 2009; Gill, 2011; Haretche, 2011), algún ordenador (Gill, 2011; Weiser y Riggio, 2010), el número de integrantes y habitaciones disponibles en un hogar (Vera y Vera, 2013), entre otras medidas. No obstante, su adecuación en distintas regiones, culturas y ámbitos socioeconómicos no siempre podría ser lo más asequible, especialmente si lo que se requiriera es seguir un enfoque individual de estratificación socioeconómica.
En cambio, con los indicadores seleccionados en el presente trabajo se logró superar todas estas posibles limitantes. Siendo concretos, se pudo ajustar la formulación de aquellas consultas que lo necesitaban, con el fin de hacerlas más claras y perceptibles para los individuos a los cuales estuvieron dirigidas (que no necesariamente tenían el rol de jefes de hogar). Así, se proporcionó una visión más completa y precisa de su situación socioeconómica individual. Específicamente, la Tabla 3 muestra que, en 2019, hubo una alta concentración de usuarios del transporte urbano con educación universitaria o superior técnica que frecuentaban la avenida Francisco Bolognesi en la ciudad de Chiclayo. De hecho, una parte significativa de estas personas se había graduado de alguna universidad. Sumado a esto, la mayoría laboraba de forma independiente o por cuenta ajena (empleados), seguidos por empleadores y trabajadores familiares.
Asimismo, era notoria la presencia de individuos con un ingreso monetario al mes mayor a 830 soles, pero sin sobrepasar los 2620 soles. En cuanto al tipo de servicio de salud al que accedían, se aprecia que una gran parte hacía uso de seguros sociales u hospitales de las Fuerzas Armadas, la policía, la Solidaridad o el Ministerio de Salud. También se evidencia que mayormente estos usuarios vivían en apartamentos o en casas de su propiedad. Del mismo modo, más de la mitad habitaba viviendas con pisos de mayólica, loseta o cerámica, y casi todos tenían en sus hogares cocina, refrigeradora e internet. Por último, un considerable número de esta DTU contaba con lavadora en sus respectivos domicilios y una menor fracción teléfono fijo.
Sin embargo, aunque mínima, una parte de la DTU encuestada oficialmente solo había acabado la secundaria o, más bien, tenía estudios de postgrado. Había quienes trabajaban de ambulantes. Asimismo, por su trabajo, ciertos usuarios percibían no más de 830 soles al mes. Se habitaban viviendas improvisadas o en callejón. El piso de algunos hogares era de tierra o arena. Además, por salud, se recurría a postas médicas, farmacias o, incluso, a naturistas.
Tabla 3. Usuarios del transporte que frecuentaban la avenida Francisco Bolognesi de Chiclayo en 2019 según algunas de sus características socioeconómicas individuales.
|
Características |
Categorías |
Casos (en %) |
|
Nivel de estudios: |
‣ Secundaria completa |
5.4 |
|
‣ Superior técnico incompleto |
6.9 |
|
|
‣ Superior técnico completo |
22.5 |
|
|
‣ Estudios universitarios incompletos |
22.1 |
|
|
‣ Estudios universitarios completos |
32.2 |
|
|
‣ Maestría |
7.2 |
|
|
‣ Doctorado |
3.6 |
|
|
|
|
|
|
Condición laboral actual: |
‣ Ambulante |
6.2 |
|
‣ Trabajador familiar |
13.4 |
|
|
‣ Trabajador independiente |
36.2 |
|
|
‣ Trabajador dependiente |
30.8 |
|
|
‣ Empleador |
13.4 |
|
|
|
|
|
|
Ingresos monetarios (al mes): |
‣ Menos o hasta S/ 830 |
9.1 |
|
‣ Más de S/ 830 hasta S/ 1040 |
27.5 |
|
|
‣ Más de S/ 1040 hasta S/ 1740 |
22.8 |
|
|
‣ Más de S/ 1740 hasta S/ 2620 |
26.8 |
|
|
‣ Más de S/ 2620 |
13.8 |
|
|
|
|
|
|
Tipo de vivienda: |
‣ Vivienda improvisada |
1.8 |
|
‣ Vivienda en callejón |
4.7 |
|
|
‣ Vivienda en quinta |
19.6 |
|
|
‣ Apartamento en edificio |
39.9 |
|
|
‣ Casa independiente |
34.1 |
|
|
|
|
|
|
Material base en el piso del hogar: |
‣ Tierra / Arena |
2.2 |
|
‣ Cemento sin pulir (falso piso) |
10.9 |
|
|
‣ Cemento pulido / Tapizón |
28.3 |
|
|
‣ Mayólica / Losetas / Cerámicos |
56.2 |
|
|
‣ Parquet / Madera pulida / Alfombra / Mármol / Terrazo |
2.5 |
|
|
|
|
|
|
En su hogar cuenta con: |
‣ Cocina |
100.0 |
|
‣ Refrigeradora |
99.6 |
|
|
‣ Lavadora |
82.6 |
|
|
‣ Teléfono fijo |
65.9 |
|
|
‣ Servicio doméstico |
6.9 |
|
|
‣ Internet |
97.8 |
|
|
|
|
|
|
Tipo de acceso al servicio de salud: |
‣ Posta médica / Farmacia / Naturista |
17.0 |
|
‣ Hospital del Ministerio de Salud / Hospital de la Solidaridad |
25.7 |
|
|
‣ Seguro social / Hospital de las FFAA / Hospital de la policía |
30.1 |
|
|
‣ Médico particular en consultorio |
17.0 |
|
|
‣ Médico particular en clínica privada |
10.1 |
|
|
Observaciones |
|
276 |
Nota. FFAA = Fuerzas Armadas. Ningún encuestado contestó no tener estudios o solo contar con primaria incompleta, completa o secundaria incompleta. Se consideró las cinco categorías oficiales de la variable ingresos.
Estos hallazgos, por tanto, sugieren que la avenida Francisco Bolognesi era una vía clave para personas que, principalmente, tenían un nivel medio o bajo superior de educación y ocupación, recibían montos bajo inferiores por su trabajo y residían en viviendas de mediana o alta calidad. No obstante, algunos usuarios percibían ingresos laborales muy bajos, su acceso a servicios de salud era limitado y vivían en domicilios de baja habitabilidad. Por ello, se requieren políticas públicas que aborden todas estas desigualdades y mejoren, en este contexto, la infraestructura vial, promoviendo una movilidad urbana inclusiva y equitativa.
Calidad de los indicadores seleccionados
En la matriz de correlaciones de la Tabla 4 puede apreciarse que hubo pruebas suficientes para no aceptar que las variables observables EDUC, OCUP, INGR, TIPV, MBPH, ACTH y TASS estaban incorreladas. Esto, tanto al utilizar información preliminar como oficial (ver por debajo o encima de la diagonal principal de la matriz, en ese orden). En ambos casos, los coeficientes de correlación fueron estadísticamente significativos (con al menos un p < .01) e importantes. Igualmente, cada poder estadístico post hoc (mayor a .86) indica una alta capacidad del test de correlación de Pearson para detectar los efectos anteriores en la DTU objetivo, sugiriendo que las relaciones observadas tenían una gran posibilidad de ser reales. A su vez, los determinantes obtenidos eran cercanos a cero: 0.009 en el pilotaje y 0.013 de forma definitiva, lo que revelaba una muy considerable intercorrelación entre los indicadores evaluados.
Tabla 4. Matriz de correlaciones entre los indicadores del nivel socioeconómico individual en usuarios del transporte urbano que se encuestaron durante el 2019.
|
Indicadores evaluados |
TASS |
EDUC |
OCUP |
INGR |
TIPV |
MBPH |
ACTH |
|
Tipo de acceso al servicio de salud (TASS) |
1.000 |
.616*** |
.714*** |
.854*** |
.466*** |
.445*** |
.495*** |
|
– |
1.000 |
1.000 |
1.000 |
1.000 |
1.000 |
1.000 |
|
|
|
|
|
|
|
|
|
|
|
Nivel educativo (EDUC) |
.630*** |
1.000 |
.718*** |
.659*** |
.323** |
.509*** |
.460*** |
|
1.000 |
– |
1.000 |
1.000 |
.865 |
.998 |
.992 |
|
|
|
|
|
|
|
|
|
|
|
Condición laboral (OCUP) |
.743*** |
.616*** |
1.000 |
.786*** |
.370** |
.622*** |
.542*** |
|
1.000 |
1.000 |
– |
1.000 |
.937 |
1.000 |
1.000 |
|
|
|
|
|
|
|
|
|
|
|
Nivel de ingresos monetarios (INGR) |
.853*** |
.644*** |
.705*** |
1.000 |
.443*** |
.572*** |
.612*** |
|
1.000 |
1.000 |
1.000 |
– |
.988 |
1.000 |
1.000 |
|
|
|
|
|
|
|
|
|
|
|
Tipo de vivienda (TIPV) |
.364** |
.404*** |
.426*** |
.537*** |
1.000 |
.594*** |
.431*** |
|
.930 |
1.000 |
1.000 |
1.000 |
– |
1.000 |
.983 |
|
|
|
|
|
|
|
|
|
|
|
Material base en el piso del hogar (MBPH) |
.522*** |
.400*** |
.431*** |
.494*** |
.691*** |
1.000 |
.433*** |
|
.999 |
1.000 |
1.000 |
1.000 |
1.000 |
– |
.984 |
|
|
|
|
|
|
|
|
|
|
|
Activos del hogar (ACTH) |
.462*** |
.399*** |
.510*** |
.565*** |
.535*** |
.520*** |
1.000 |
|
.993 |
1.000 |
1.000 |
1.000 |
1.000 |
1.000 |
– |
Nota. Adaptado de Siesquén y Cabrejos (2024, p. 99). Por encima de la diagonal se ubican las correlaciones entre ítems y sus potencias estadísticas post hoc con datos definitivos, mientras que por debajo lo correspondiente al pilotaje. Los determinantes respectivos fueron .009 y .013. Se trabajo con una muestra piloto y final de 69 y 276 usuarios del transporte urbano, en ese orden. Además, se tuvo que: *p < .05, **p < .01 y ***p < .001.
La significatividad asociada al test de esfericidad de Bartlett en las etapas piloto (χ2 = 302.751, gl = 21) y oficial (χ2 = 1182.399, gl = 21) ratificaba la ausencia de pruebas suficientes para no rechazar la hipótesis nula de incorrelación entre los ítems indicados (con un p < .001 en ambas instancias). Además, en el pilotaje se obtuvo una medida KMO de .852, valor que oficialmente fue de .863, constatándose de esta manera que la matriz de correlaciones presentada en la Tabla 4 era apta para la factorización (según lo aconsejado por Kaiser, 1970).
Dado estos resultados, se procedió a realizar el AFE. Como se observa en la Tabla 5, eran dos constructos (no solo uno) los que explicaban un mayor porcentaje de la varianza común de las respuestas definitivas a los reactivos analizados, con saturaciones superiores a los umbrales de .30 o .40 establecidos por Bandalos y Finney (2019). El primer factor (F1) se asociaba más con EDUC, OCUP, INGR y TASS, mientras que el segundo (F2) con TIPV, MBPH y ACTH. No obstante, el test de bondad de ajuste advertía que tanto este modelo como el basado en AV > 1 (ya sea usando información piloto u oficial) representaban adecuadamente las relaciones entre dichos ítems, sin dejar claro cuál ofrecía un mejor ajuste en general.
Tabla 5. Matrices factoriales y de patrón relacionadas con el concepto nivel socioeconómico individual en usuarios del transporte urbano encuestados durante el 2019.
|
Indicadores |
Piloto, AV > 1: F1 |
Fase oficial, AV > 1: F1 |
NFE = 2: F1 |
F2 |
|
TASS |
.877 |
.895 |
.978 |
|
|
EDUC |
.738 |
.700 |
.658 |
|
|
OCUP |
.861 |
.782 |
.760 |
|
|
INGR |
.934 |
.930 |
.906 |
|
|
TIPV |
480 |
.592 |
|
.847 |
|
MBPH |
.651 |
.564 |
|
.843 |
|
ACTH |
.625 |
.616 |
|
.453 |
|
VCE |
.568 |
.545 |
.562 |
.100 |
|
|
|
|
|
|
|
c2 |
33.637 |
154.310 |
18.695 |
|
|
gl |
14 |
14 |
8 |
|
|
p |
.002 |
< .001 |
.017 |
|
Nota. Adaptado de Siesquén y Cabrejos (2024, pp. 102, 103). AV = autovalores; NFE = número de factores extraídos; F1 = factor 1; F2 = factor 2; TASS = tipo de acceso al servicio de salud; EDUC = nivel educativo; OCUP = condición laboral; INGR = nivel de ingresos monetarios; TIPV = tipo de vivienda; MBPH = material base en el piso del hogar; ACTH = activos del hogar; VCE = varianza común explicada. Para la extracción factorial se aplicó la máxima verosimilitud y en la rotación el método Oblimin directo con normalización Kaiser y delta = 0. Solo se muestran las cargas factoriales mayores a .40. La segunda y tercera columna son las matrices factoriales del pilotaje y la etapa oficial (partiendo de AV > 1, luego de cinco iteraciones). La última columna presenta la matriz de patrón que solo se obtuvo en la última etapa (al fijar en dos el NFE, luego de nueve iteraciones y otras cinco para la rotación). Se trabajo con una muestra piloto y oficial de 69 y 276 usuarios del transporte urbano, de manera correspondiente.
Adicionalmente, la correlación entre F1 y F2 (![]() = .666) no
solo ratificó la correcta elección del tipo de método de rotación oblicua
aplicado, sino que también sugería la existencia de un factor de segundo orden,
lo cual no podía ser probado mediante el AFE. Tampoco era posible verificar si
cada indicador evaluado lo era únicamente del factor que parecía serlo, sin
importar cuál de los dos modelos anteriormente mencionados se estuviera examinando.
= .666) no
solo ratificó la correcta elección del tipo de método de rotación oblicua
aplicado, sino que también sugería la existencia de un factor de segundo orden,
lo cual no podía ser probado mediante el AFE. Tampoco era posible verificar si
cada indicador evaluado lo era únicamente del factor que parecía serlo, sin
importar cuál de los dos modelos anteriormente mencionados se estuviera examinando.
Es por ello que se realizó un AFC 1 para probar los resultados del primer AFE (cuya extracción factorial estaba basada en AV > 1). En cambio, con el AFC 2 y su reespecificación (el AFC 3), se ratificó los hallazgos logrados al fijar dos factores en el segundo AFE. Así, se realizaron tres tipos de MEE-BC, cuyos principales resultados los muestra la Figura 2.
Figura 2. Modelos de ecuaciones estructurales utilizados en la validación confirmatoria de los indicadores del NSE de los usuarios del transporte urbano investigados en 2019.
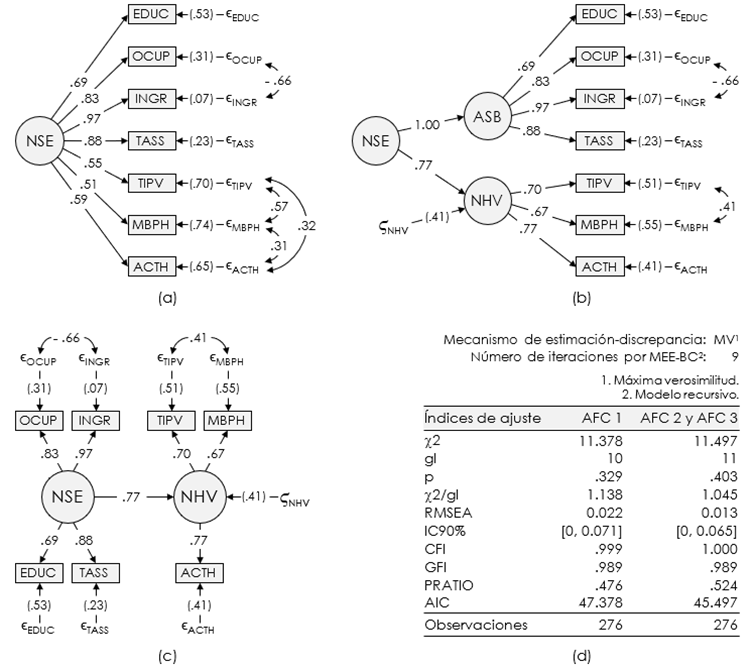
Nota. Adaptado de
Siesquén y Cabrejos (2024, p. 109). ASB = aspectos básicos;
MEE˗BC
= modelado de ecuaciones estructurales (MEE) basado en covarianzas; NSE = nivel
socioeconómico;
NHV = nivel de habitabilidad de la vivienda; ![]() =
error de medida de NHV; EDUC = nivel educativo; TASS = tipo de acceso al
servicio de salud; OCUP = condición laboral; INGR = nivel de ingresos
monetarios; ACTH = activos del hogar; TIPV = tipo de vivienda; MBPH = material
base en el piso del hogar. Los diagramas en los paneles (a), (b) y (c) son del
análisis factorial confirmatorio (AFC) de orden uno (AFC 1), dos (AFC 2) y su
ajuste (AFC 3). La varianza de cada error de medida
=
error de medida de NHV; EDUC = nivel educativo; TASS = tipo de acceso al
servicio de salud; OCUP = condición laboral; INGR = nivel de ingresos
monetarios; ACTH = activos del hogar; TIPV = tipo de vivienda; MBPH = material
base en el piso del hogar. Los diagramas en los paneles (a), (b) y (c) son del
análisis factorial confirmatorio (AFC) de orden uno (AFC 1), dos (AFC 2) y su
ajuste (AFC 3). La varianza de cada error de medida ![]() se
muestra entre paréntesis. Se reportan coeficientes de correlación y regresión
estandarizados (con un valor p < .001).
se
muestra entre paréntesis. Se reportan coeficientes de correlación y regresión
estandarizados (con un valor p < .001).
Por su parte, el panel (d) de la Figura 2 muestra un resumen del análisis de la bondad de ajuste de dichos modelos. Como se observa, el AFC 3 fue el que mejor se adecuó a los datos oficiales. Pese a que el AFC 2 era igual de parsimonioso, carecía de validez discriminante y convergente. En el panel (b) se aprecia que esto se debió a la magnitud de influencia del factor NSE en ASB, corroborándose de esta manera la inexistencia de esta última dimensión.
Así, lo detallado en el panel (c) sugiere que los siete reactivos evaluados eran indicadores del NSE individual, ya sea de forma directa (como en el caso de EDUC, OCUP, INGR y TASS) o indirectamente (a través del factor NHV, para el caso de TIPV, MBPH y ACTH). Sin embargo, este NSE se reflejaba más en INGR, explicando una gran parte de su varianza (R2 = .931). En menor medida, lo hacía en TASS (R2 = .772) y OCUP (R2 = .691). Pero, aún menos, en EDUC (R2 = .473), revelando la presencia de variables omitidas que explicaban mejor este ítem, como las políticas públicas que influyen en la calidad del sistema educativo.
Respecto a esto último, la Tabla 3 muestra que un mayor porcentaje de las personas analizadas tenía estudios universitarios concluidos, seguido por las que completaron su educación superior técnica. Asimismo, la literatura señala que la desregulación del sistema educativo peruano, por medio del Decreto Legislativo N° 882 en 1996, ha provocado un sostenido aumento de la oferta universitaria (Yamada et al., 2017), lo que se ha asociado estrechamente a una baja en la calidad educativa de aquellas instituciones creadas durante la posdesregulación (Lavado et al., 2014). De esta manera, pese a ubicarse en un mismo NSE individual, muchos de los usuarios con una educación superior posiblemente no tuvieron la formación requerida por el mercado laboral, lo que explicaría la limitada influencia del factor NSE en al reactivo EDUC.
Además, la correlación de ˗.667 entre los residuales de INGR y OCUP indica que, aun con la misma clase de empleo, ciertos usuarios recibían al mes menos o más ingresos de lo esperado. En Perú, hay una gran brecha salarial entre trabajadores formales e informales, con la mayoría laborando de modo independiente o como asalariados (Manayay, 2020). De hecho, en 2019, el 75.4% de los trabajadores en la región Lambayeque eran informales (Ministerio del Trabajo y Promoción del Empleo [MTPE], 2020), en tanto que la mayor parte de la DTU analizada fueron trabajadores independientes o empleados (ver Tabla 3). Por tanto, la disparidad en sus retornos laborales podría haberse debido a factores relacionados en los sectores formal e informal, como el nivel educativo y la experiencia laboral (Badullahewage y Badullahewage, 2021; Santoso et al., 2022; Srivastava, 2019), esta última junto a la edad, el género, las capacitaciones recibidas y la clase social (Srivastava, 2019; Wulandari et al., 2018), más las diferencias y segmentación institucional del mercado laboral (Santoso et al., 2022; Srivastava, 2019).
De forma similar, el constructo NHV se veía reflejado mucho más en el ítem ACTH (R2 = .586) que en TIPV (R2 = .494) o MBPH (R2 = .453). No obstante, era mayor la influencia que recibía del factor NSE (R2 = .594). Más bien, la correlación de .499 entre los residuos de los reactivos TIPV y MBPH implica que hubo clústeres dentro de la muestra que, a pesar de seguir un patrón general positivo en cuanto a su NSE, mostraron diferencias en sus niveles de concentración de datos. Como anteriormente se ha planteado, este desajuste podría haberse debido a su nivel de pobreza de tipo no monetaria (Feres y Mancero, 2001; Villatoro, 2017).
Ahora bien, mediante los modelos alfa y aleatorio bifactorial se halló que los siete ítems usados en la construcción de un ISE individual presentaron una buena consistencia interna, según la clasificación de George y Mallery (2010), tanto en la etapa preliminar (CAC = CCIMP = .895, IC95% [.852, .929]) como de forma oficial (CAC = CCIMP = .892, IC95% [.871, .910]). Podría decirse que este grupo de ítems si evaluaban lo mismo, teniendo éxito al segregar sus distintas particularidades, siendo esto fiable al 95.0%. Además, en ambas instancias, su reproducibilidad se veía mermada al utilizarse solo uno de ellos (fase piloto: CCIMU = .549, IC 95%: .452, .651, F(68, 408) = 9.527; fase decisiva: CCIMU = .541, IC95% [.491, .592], F(275, 1650) = 9.243; con un valor de prueba de cero y un p < .001 en cada análisis). Esto último respalda la importancia de emplear varios indicadores al requerir una medida más confiable y precisa del NSE individual, similar a lo sugerido por la literatura (Sirin, 2005; White, 1982).
A su vez, los resultados de haber calculado la VME con la información derivada del AFC 3 (el MEE-BC más parsimonioso) mostraban que, en promedio, el 71.4% de la varianza de los ítems EDUC, OCUP, INGR y TASS era explicada por el factor NSE. De igual manera, el constructo NHV explicaba, en promedio, el 51.1% de la varianza de los reactivos TIPV, MBPH y ACTH. Ambos porcentajes superaban el umbral mínimo sugerido por Baharum et al. (2023) y Fornell y Larcker (1981), revelándose de este modo la idoneidad de dichas agrupaciones de indicadores para la medición empírica de sus respectivos constructos (i.e., que estas variables observables representaban apropiadamente al factor latente que les correspondía).
En resumen, los hallazgos obtenidos confirmaron el cumplimiento de los criterios de validez y confiabilidad de los siete ítems anteriormente mencionados. No obstante, el método empleado para esta verificación es algo inusual en algunos aspectos. Primero, porque se hizo uso del AFE y el MEE-BC (que incluyó el AFC) en la etapa de validación. Segundo, que se utilizó el CAC, CCIMU, CCIMP y la VME para ofrecer una mejor evaluación de la fiabilidad. Por el contrario, al realizar ambas evaluaciones, otros trabajos han preferido usar ciertos criterios basados en la literatura teórica y empírica (Caro y Cortés, 2012; Haretche, 2011). Paralelamente, en distintos estudios solo se ha examinado que tan fiable era la escala que adecuaron (Naushad, 2022; Vera y Vera, 2012) o validaron su contenido (Ensminger et al., 2000). Es más, varias investigaciones simplemente no consideraron necesario evaluar la calidad de los reactivos que utilizaron en la estimación del ESE de las familias (Artola y Blumethal, 2015; Caro, 2002; Cuellar et al., 2016; Dickinson y Adelson, 2014; Fotso y Kuate-Defo, 2005; Fujihara, 2020; Gill, 2011; K. Morales et al., 2021; May, 2006; MINEDU, 2018; Oakes y Rossi, 2003; V. Rodríguez y Espinoza, 2015; Weiser y Riggio, 2010) o la escala que ajustaron (Weiser y Riggio, 2010).
Análisis del ISE individual
Como ya se ha señalado, en este estudio se calcularon dos índices socioeconómicos, pero desde una perspectiva individual. El primero de ellos se obtuvo estandarizando los puntajes del factor NSE, imputados del AFC 3, que fue el tipo de MEE-BC que mejor se ajustó a los datos captados por los siete ítems escogidos. Este método difiere de otros que, para medir el ESE familiar, han usado ciertas técnicas estadísticas avanzadas. Tal es el caso de los modelos MIMIC (Dickinson y Adelson, 2014; Oakes y Rossi, 2003), el método bayesiano multinivel (May, 2006), el análisis de regresión (Fujihara, 2020) o el modelo de Rasch (Haretche, 2011). También se han aplicado los análisis de correspondencia múltiple y escalamiento óptimo (Artola y Blumethal, 2015), así como el análisis de componentes principales (Caro, 2002; Caro y Cortés, 2012; Fotso y Kuate-Defo, 2005; Gill, 2011; Naushad, 2022), su modalidad no lineal (K. Morales et al., 2021) o en combinación con el método de asignación óptima (Cuellar et al., 2016).
Los valores del segundo ISE individual resultaron de tipificar la suma de los puntajes asignados a las respuestas de dichos indicadores (i.e., las variables EDUC, OCUP, INGR, TIPV, MBPH, ACTH y TASS). Esta manera de obtener un ISE contrasta con otras en donde las puntuaciones de las variables utilizadas se sumaron (Weiser y Riggio, 2010), promediaron (Ensminger et al., 2000), ponderaron con datos basados en el juicio de expertos (V. Rodríguez y Espinoza, 2015) o se tipificó este valor esperado, tras ponderarlo con información tomada de la literatura (Caro, 2002) o de análisis previos de componentes centrales (MINEDU, 2018).
Además, se calcularon dos índices de habitabilidad de las viviendas ocupadas por las personas analizadas en la presente investigación, con base en los resultados que se obtuvieron en la etapa de validación de los reactivos evaluados. No obstante, debe aclararse que ambas mediciones se efectuaron únicamente para disponer de un marco de referencia adicional, a fin de contrastar y complementar los hallazgos brindados por los anteriores índices socioeconómicos individuales. De esta forma, se proporcionó una perspectiva mucho más completa y matizada de la situación socioeconómica y habitacional de dichos usuarios del transporte urbano.
Así, en el panel (a) de la Figura 3 se observan ciertas diferencias entre el ISE individual basado en la tipificación de los puntajes derivados del AFC 3 (ISEI-BAFC 3 para abreviar) y el que se basó en la estandarización de la suma de los códigos de las respuestas a los ítems anteriormente evaluados (en adelante, ISEI-BESC). Para ser más específicos, los valores de este último índice se posicionaban más cerca de su promedio (Mdn = 0.035), mientras que los del ISEI-BAFC 3 tendían a estar levemente por encima de cero (Mdn = 0.114). A pesar de esto, sus distribuciones parecían ser casi normales, aunque con ligeras desviaciones (ISEI-BAFC 3: Asimetría = 0.039, Curtosis = -0.889; ISEI-BESC: Asimetría = -0.241, Curtosis = -0.393).
También se aprecia que, según su IHV derivado de la tipificación de los valores resultantes del AFC 3 (i.e., su IHV-BAFC 3), la mayor parte de los encuestados habitaba viviendas en mejores condiciones que la media (Mdn = 0.168, Curtosis = 0.402). Pese a ello, algunos usuarios vivían en domicilios, por mucho, menos habitables que los de esta gran mayoría (Asimetría = -0.806). De hecho, el IHV obtenido al normalizar la suma de los códigos de las respuestas a los reactivos TIPV, MBPH y ACTH (con siglas IHV-BESC) mostraba estos mismos rasgos, pero de manera más acentuada (Mdn = 0.502, Asimetría = -1.260, Curtosis = 1.769).
Desde luego, tanto el ISEI-BAFC 3 como el ISEI-BESC tendían a presentar distribuciones más simétricas y normales en contraste con el IHV-BAFC 3 o el IHV-BESC, los cuales mostraban una distribución cada vez más sesgada hacia medidas más bajas. Esto significa que hubo mayor diversidad y desigualdad en las condiciones de las viviendas habitadas por la DTU encuestada oficialmente, reflejadas en valores mucho más alejados del promedio.
Figura 3. Distribución, densidad, dispersión y umbrales de clasificación: El caso del ISEI y el IHV de los usuarios del transporte urbano encuestados oficialmente en 2019.
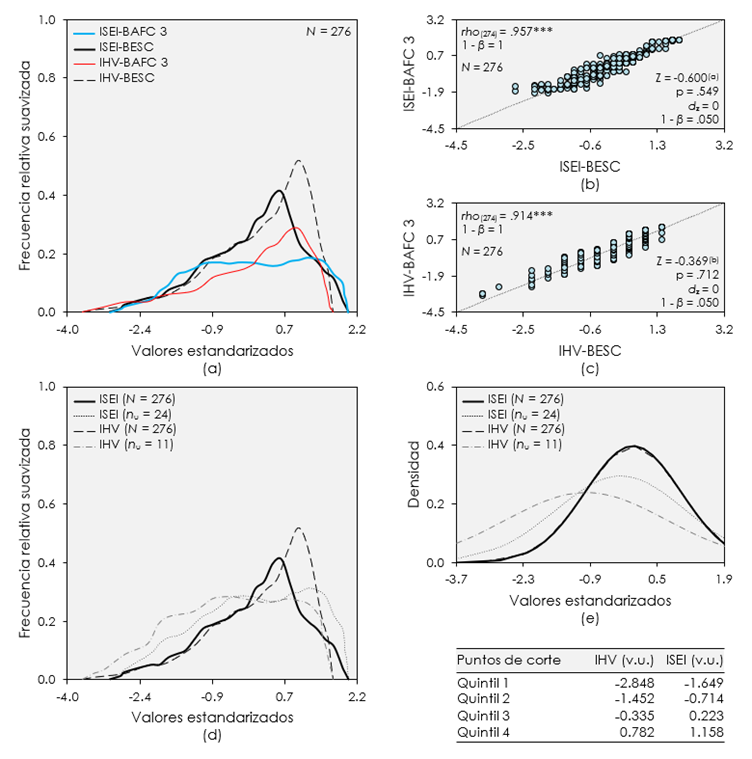
Nota. ISEI = índice socioeconómico (ISE) individual; IHV = índice de habitabilidad de la vivienda; BAFC 3 = basado en la tipificación de puntajes obtenidos del análisis factorial confirmatorio de segundo orden reajustado; BESC = basado en la estandarización de la suma de códigos de las respuestas a los ítems evaluados. El subíndice u enuncia al grupo de valores únicos (v.u.). En el panel (a) se grafican las distribuciones del ISEI-BAFC 3, ISEI-BESC, IHV-BAFC 3 e IHV-BESC. La dispersión por tipos de índices se muestra en los paneles (b) y (c), incluidos sus coeficientes rho de Spearman (con un ***p < .001) y los estadísticos del test de Wilcoxon basado en rangos (a)negativos y (b)positivos, en ese orden (con sus valores p y tamaños del efecto). También se reporta el poder estadístico post hoc de estas pruebas. La distribución y densidad del ISEI e IHV que fueron elegidos por su eficiencia y sencilles en cuanto a su cálculo, así como de sus v.u., se grafican en los paneles (d) y (e), omitiéndose en la leyenda la sigla BESC por ser redundante. Se incluye una tabla con los quintiles oficiales de estos índices (indicando que se consideró para ello sus v.u.).
Por otra parte, en el panel (b) de la Figura 3 se observa que había una muy fuerte relación entre el ISEI-BAFC 3 y el ISEI-BESC, según el test de correlación de Spearman (el mismo que tenía una alta posibilidad de detectar este efecto en la población objetivo). Es más, ambos índices no mostraban diferencias significativas, acorde con la prueba de rangos de signos de Wilcoxon (la cual disponía de una poca probabilidad de detectar estas brechas en caso existieran). Resultados similares se aprecian en el panel (c) de la Figura 3, al evaluar la estabilidad, eficiencia, robustez y eventuales discrepancias entre el IHV-BESC y el IHV-BAFC 3.
En efecto, los hallazgos mostrados hasta ahora indican que tanto el ISEI-BAFC 3 como el ISEI-BESC eran altamente consistentes y eficaces para medir la situación socioeconómica individual de los usuarios del transporte urbano investigados. Asimismo, el IHV-BAFC 3 y el IHV-BESC medían con una gran fiabilidad y precisión las condiciones de habitabilidad de las viviendas en donde estas personas residían. No obstante, la sencillez de sus cálculos hacía del ISEI-BESC y el IHV-BESC más accesibles y fáciles de implementar. Por tanto, fueron los únicos índices que acabaron siendo elegidos (en adelante, solo ISEI e IHV para abreviar).
Las distribuciones y densidades de estas medidas y sus valores únicos se grafican en los paneles (d) y (e) de la Figura 3, en ese orden. Como se aprecia, la menor concentración de datos cerca del promedio y su mayor variabilidad, al tratarse de los puntajes únicos del ISEI e IHV, permitía evaluar con mayor precisión la distribución y diversidad de la población investigada, respecto a las condiciones de sus viviendas y su situación socioeconómica individual. Por esta razón, se calcularon cuatro puntos de corte a partir de dichas submuestras de puntuaciones no repetidas, cuyos resultados se incluyen en la tabla adjunta a la Figura 3.
Luego, estos quintiles y los rangos de puntajes sugeridos por Vera y Vera (2013) fueron usados para clasificar a cada persona de la muestra oficial en un determinado NSE individual, NHV y NSE familiar. Bajo este orden, los hallazgos obtenidos se encuentran graficados en los paneles (a), (c) y (d) de la Figura 4, dado que en el panel (b) se grafica la distribución porcentual de los hogares de la región Lambayeque según su ESE en 2019, con base en los datos actualizados de la variable Estrato Socio-Económico (ESTRSOCIAL) que se tomaron de la Encuesta Nacional de Hogares (ENAHO) sobre las condiciones de vida y pobreza.
Se visualiza, en ese sentido, que hubo una mayor concentración de usuarios en los estratos bajo superior (C) y medio (B), mientras que en el NSE marginal (E), alto (A) y bajo inferior (D) se ubicó un menor porcentaje, tanto si los umbrales aplicados provenían de un enfoque individual como familiar en esta estratificación. También se puede observar que los domicilios del 68.8% de estas personas presentaban un nivel medio o bajo superior de habitabilidad, a la vez que un 6.5% ocupaba viviendas en condiciones bajo inferiores o marginales. No obstante, si el análisis se realizaba a una escala familiar-urbano-departamental, se aprecia que el 81.7% de los hogares lambayecanos pertenecía a los segmentos D y E en 2019. El resto de familias que respondieron la ENAHO se posicionaron mayormente en la categoría C.
Estos resultados refuerzan la idea de que, para el año en cuestión, personas de diferentes niveles socioeconómicos individuales, cuyas viviendas no presentaban el mismo grado de comodidad, se transportaron a menudo por la avenida Francisco Bolognesi en la urbe de Chiclayo. Es más, parecía ser que este tipo de DTU provenía de distintos estratos familiares. Aunque, cabe reiterar que hubo una mayor presencia de usuarios con un mejor NSE y NHV, pero sin llegar a un nivel alto. Esta situación se dio a pesar de que la gran mayoría de los hogares en el departamento de Lambayeque, a los cuales la muestra oficial pertenecía (debido al tipo de muestreo aplicado en el presente estudio), se ubicaron en las dos categorías socioeconómicas más bajas. Al parecer, solo los integrantes de una pequeña fracción de hogares lambayecanos frecuentaron la anterior vía en 2019, a bordo de algún medio de transporte motorizado permitido, ya que el resto pudo haberla transitado como peatones o utilizado otras rutas de viaje.
Figura 4. Usuarios del transporte urbano que frecuentaban la avenida Francisco Bolognesi en Chiclayo y familias de la región Lambayeque, distribuidas según su NSE en 2019.
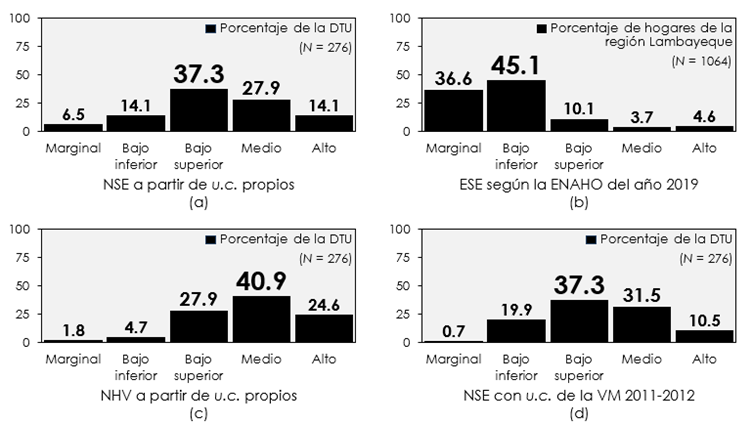
Nota. Adaptado de Siesquén y Cabrejos (2024, p. 115). NSE = nivel socioeconómico; NHV = nivel de habitabilidad de la vivienda; DTU = demanda del transporte urbano (aclarando que hacía referencia a los usuarios del transporte urbano); ESE = Estrato socioeconómico; u.c. = umbrales de clasificación; VM = versión modificada en el estudio efectuado por Vera y Vera (2013); ENAHO = encuesta nacional de hogares. Las categorías para los estratos derivados de la ENAHO de 2019 se adaptaron según lo indicado por Vera y Vera (2013).
Otro detalle notado es que un 3.6% y 5.8% de la DTU ubicada individualmente en los estratos A y E se situaban, respetivamente, en los niveles B y D si su distribución socioeconómica era familiar. Este hecho se debió a que la mayoría de los limites inferiores y superiores de los cinco rangos socioeconómicos familiares sugeridos por Vera y Vera (2013) diferían de los obtenidos en esta investigación a partir de la versión no estandarizada del ISEI elegido, tal como se puede apreciar en la Tabla 6. Igualmente, no se debe olvidar que este índice fue el que se sometió a ambas formas en las que los usuarios analizados se estratificaron.
Tabla 6. Niveles socioeconómicos: Categorías, niveles nacionales y rangos de puntajes según un enfoque individual y la versión familiar propuesta por Vera y Vera (2013).
|
Niveles |
NSE |
Categoría |
Puntajes para el ISEI(a) |
Puntajes de la VM 2011-2012 |
|
1 |
A |
Alto |
32 – 35 |
33 o más |
|
2 |
B |
Medio |
27 – 31 |
27 – 32 |
|
3 |
C |
Bajo superior |
22 – 26 |
21 – 26 |
|
4 |
D |
Bajo inferior |
17 – 21 |
13 – 20 |
|
5 |
E |
Marginal |
7 – 16 |
5 – 12 |
Nota. NSE = nivel socioeconómico; ISEI = índice socioeconómico individual; VM = versión modificada por Vera y Vera (2013, p. 44); (a)Su cálculo se basó en la suma de los códigos de las respuestas a los siete indicadores evaluados en el presente estudio (i.e., las variables observables EDUC, OCUP, INGR, TASS, TIPV, MBPH y ACTH).
Esta particularidad en los resultados obtenidos muestra que posiblemente la población objetivo no siempre se ubicó en un determinado NSE si se consideraba su situación individual o familiar en 2019, especialmente una parte de aquella DTU que individualmente se situó en el mayor o menor nivel de la escala socioeconómica abordada. Es probable que los ingresos y recursos de otros miembros de sus hogares influyeron en esta redistribución. Por ejemplo, una persona que se hallaba de forma individual en el estrato A pudo haber descendido a la clase B debido a los limitados medios económicos de algunos o todos los integrantes de su familia. Asimismo, es posible que, por el apoyo económico de sus familiares, un usuario situado en el NSE individual E mejorara, al menos en una categoría, su NSE familiar.
Lo anterior sugiere que la estratificación socioeconómica bajo un enfoque individual puede ser un factor clave para entender las necesidades y comportamientos de movilidad en el transporte urbano. Al tomar en cuenta las diferencias personales dentro de los hogares, los planificadores y responsables de políticas podrían diseñar intervenciones más efectivas y personalizadas, a fin de mejorar la accesibilidad y la equidad en el transporte urbano.
El aporte de este estudio ha sido desarrollar una nueva forma de estratificación socioeconómica basada en un enfoque individual y haber aplicado esta técnica a un grupo específico de usuarios del transporte urbano que, durante el 2019, realizaron viajes frecuentes por una vía importante de la ciudad de Chiclayo: la avenida Francisco Bolognesi. Esto incluyó la selección, aplicación y evaluación de la validez y fiabilidad de los indicadores educación, condición laboral, ingresos monetarios, tipo de acceso al servicio de salud, tipo de vivienda, número de activos y material base de sus pisos, su utilización en el cálculo de dos índices socioeconómicos individuales, la elección de solo uno de ellos y su distribución en cinco niveles. Este método permite clasificar a las personas según su NSE, por lo cual podría superar las propuestas enfocadas en la situación familiar, que pueden verse afectadas por variables como la estructura, dependencia económica de sus integrantes y las dinámicas producidas al interior de los hogares.
Sobre la calidad de dichos ítems, los hallazgos oficiales revelaron que estaban interrelacionados significativamente (test de Bartlett, p < .001) y se podían factorizar (KMO = .863). Es así que, mediante el tercer y último MEE-BC se logró confirmar su validez (test chi cuadrado, p = .403; RMSEA = 0.013, IC90% [0, 0.065]; CFI = 1, GFI = .989) y comprobar que eran fiables, debido a que uno de los dos factores en este modelado, denominado NSE (bajo un enfoque individual), explicaba – en promedio – el 71.4% de la varianza de los ítems educación, ocupación, ingresos y acceso a salud, además de que influía significativamente en el factor restante, nombrado NHV (λ = .770, p < .001), el cual podía medirse – en la práctica – a través de los indicadores tipo de vivienda, material base de los pisos y número de activos (VME = .511). De hecho, la fiabilidad de estas variables observables (CAC = CCIMP = .892, IC95% [.871, .910]) se veía afectada al solo usarse una de ellas (CCIMU = .541, IC95% [.491, .592], F(275, 1650) = 9.243, valor de prueba = 0, p < .001). Por lo tanto, con este grupo de ítems podría recopilarse información mucho más válida y fiable que con otros reactivos, cuya robustes no se ha llegado a probar adecuadamente. Los resultados obtenidos también enfatizan la importancia del NSE individual en la mejora del NHV de las personas analizadas y destacan la necesidad de emplear múltiples indicadores para una evaluación más precisa y confiable de estas variables latentes.
En cuanto a los dos índices socioeconómicos individuales calculados a partir de los indicadores anteriores, ambos mostraron una eficiencia similar (test de Spearman, rho(274) = .957, p < .001, 1 - β = 1; test de Wilcoxon, p = .549, dz = 0). No obstante, solo uno de ellos se obtenía de forma más sencilla (solo se requería estandarizar la suma de los códigos de las respuestas a los ítems elegidos, en vez de tipificar los puntajes del factor NSE individual que previamente debían ser imputados del mencionado MEE-BC, tal como se dio al calcular el otro ISEI). Por ello, fue el único que se clasificó en cinco niveles, pero empleando los quintiles de sus valores únicos. El fin de omitir las reiteraciones de sus puntajes era mitigar el sesgo que ocasionaban y así evaluar de manera más precisa y equilibrada la distribución y diversidad socioeconómica individual de la DTU analizada. Esto subraya la eficacia de dicha medida, sin sacrificar precisión, ofreciendo de esta forma una herramienta mucho más equitativa y representativa.
Haber distribuido este ISEI en el grupo de usuarios estudiados, del modo como se hizo, reveló que un 37.4% se ubicó en el estrato C y en los segmentos B, A, D y E un 27.9%, 14.1%, 14.1% y 6.5%, en ese orden. Sin embargo, cuando se aplicaban los rangos de clasificación propuestos por Vera y Vera (2013), un 3.6% y 5.8% de aquellos inicialmente posicionados en los estratos individuales A y E pasaban a situarse en las categorías familiares B y D, respectivamente. Este hecho evidencia cómo el perfil socioeconómico personal de algunos integrantes de la población objetivo puede no estar debidamente reflejado en su ESE familiar, lo que podría conducir a una subestimación de sus necesidades y conductas reales al transportarse.
De manera que, adoptar el método de estratificación socioeconómica individual implementado en el presente estudio resulta ser fundamental para comprender mejor los patrones de movilidad de las personas investigadas. Además, esta técnica ayudaría a diseñar políticas más justas en el sector del transporte urbano, incluyendo la posibilidad de ajustar las intervenciones a los grupos más vulnerables, promoviendo de esta forma una mayor equidad social.
No obstante, ciertos aspectos notados en la validación confirmatoria de los ítems seleccionados merecen atención. Por ejemplo, el nivel educativo mostró una capacidad limitada para reflejar el NSE individual (R2 = .473), menor a la del factor NHV (R2 = .594), el cual explicó un 45.3%, 49.4% y 58.9% de la variabilidad del número de activos, el tipo de vivienda y material base de los pisos. Asimismo, la correlación de .499 entre los residuales de estos dos últimos indicadores implicó la presencia de clústeres con diferencias en la concentración de sus datos. En cambio, la correlación de -.667 entre los residuos de los ítems ingresos y ocupación sugería variaciones salariales en empleos similares, lo que subraya la complejidad de estas relaciones (con factores adicionales que aún no han sido incluidos en el mencionado MEE-BC).
Para fortalecer el análisis y responder a estas observaciones, se debería ampliar la variedad de ítems utilizados, integrando variables que puedan capturar mejor las características particulares del empleo y las condiciones económicas de la región Lambayeque. Igualmente, implementar herramientas analíticas, como el análisis de conglomerados, permitiría la detección de patrones ocultos y subgrupos concretos en la población estudiada, proporcionando una comprensión más detallada de las dinámicas socioeconómicas individuales observadas.
También es importante contemplar que los resultados obtenidos en este trabajo se apoyaron en datos específicos que fueron recopilados en 2019 y para un contexto particular de la ciudad de Chiclayo, lo que podría no representar totalmente otras realidades urbanas. Es por ello que, en futuras investigaciones se debería ampliar el alcance temporal y geográfico del estudio, tomar en cuenta otros contextos urbanos y explorar variables adicionales que podrían estar influyendo en la estratificación socioeconómica individual y la movilidad urbana. Adicionalmente, debería indagarse sobre cómo la planificación y las políticas de transporte urbano se ven afectadas por la estratificación socioeconómica individual. La incorporación de otras variables demográficas (como la edad, el género, la ubicación geográfica, entre otros) podrían proporcionar una visión más integral de las necesidades específicas de cada grupo.
Pese a ello, los hallazgos de este estudio subrayan la relevancia de aplicar un enfoque individual de estratificación socioeconómica para optimizar la asignación de recursos y diseñar estrategias más efectivas en la planificación urbana. Este método podría volverse en un instrumento clave para abordar desigualdades estructurales y apoyar el desarrollo sostenible de la infraestructura y movilidad en sectores urbanos de regiones como Lambayeque.
RESPONSABILIDAD ÉTICA Y LEGAL
Este trabajo se realizó respetando el código de ética de la American Psychological Association (APA), bajo las directrices para la investigación en ciencias sociales. Los participantes dieron su consentimiento informado. Además, se protegieron sus datos personales y mantuvieron en reserva sus respuestas, presentando los resultados de manera agregada.
DECLARACIÓN SOBRE EL USO DE UNTELIGENCIA ARTIFICIAL - LLM
Se ha usado Microsoft Copilot, Meta AI, Scite y SciSpace para asistir en la revisión de literatura y redacción. Pero, se han hecho las revisiones pertinentes, asumiendo la responsabilidad por la veracidad y precisión de la información y los argumentos presentados.
FINANCIAMIENTO
El presente estudio fue financiado íntegramente por el autor.
CORRESPONDENCIA
Email: jsiesquendi@unprg.edu.pe
REFERENCIAS
Acevedo-Garcia, D. y Lochner, K. A. (2003). Residential segregation and health. En Kawachi, I. y Berkman, L. F. (Eds.), Neighbourhoods and health (1.a ed., pp. 265-287). New York. Oxford Academic. https://doi.org/10.1093/acprof:oso/9780195138382.003.0012
Ariza, M. y Solís, P. (2009). Dinámica socioeconómica y segregación espacial en tres áreas metropolitanas de México, 1990 y 2000. Estudios Sociológicos, 27(79), 171-209. https://www.redalyc.org/articulo.oa?id= 59 820689006
Artola, M. F. y Blumenthal, I. R. (2015). Construcción de un índice del nivel socioeconómico del hogar urbano en la República Argentina mediante el análisis de correspondencia múltiple y escalamiento óptimo. Revista Argentina de Estadística Aplicada (RAESTA). https://untref.edu.ar/raesta/n2_art2.php
Avvisati, F. (2020). The measure of socio-economic status in PISA: a review and some suggested improvements. Large-Scale Assessments in Education, 8(1), 1-37. https://doi.org/10.1186/s40536-020-00086-x
Asociación Peruana de Empresas de Inteligencia de Mercados (APEIM, 2017). Niveles Socioeconómicos 2017 (Sede web, pp. 1-60). Lima: APEIM. http://apeim.com.pe/wp-content/uploads/2022/08/APEIM-NSE-2017-1.pdf
Asociación Peruana de Empresas de Inteligencia de Mercados (APEIM, 2018). Niveles Socioeconómicos 2018 (Sede web, pp. 1-74). Lima: APEIM. http://apeim.com.pe/wp-content/uploads/2022/08/APEIM-NSE-2018.pdf
Asociación Peruana de Empresas de Inteligencia de Mercados (APEIM, 2019). Niveles Socioeconómicos 2019 (Sede web, pp. 1-24). Lima: APEIM. http://apeim.com.pe/wp-content/uploads/2022/08/NSE-2019-Web-Apeim-2.pdf
Azócar, G., Henríquez, C., Valenzuela, C. y Romero, H. (2008). Tendencias sociodemográficas y segregación socioespacial en Los Ángeles, Chile. Revista de geografía Norte Grande, (41), 103-128. http://dx.doi.org/10.4067/S0718-34022008000300006
Badullahewage, B. P. P. y Badullahewage, S. U. (2021). Wage Difference Between Formal Sector and Informal Sector Jobs; With Special Reference to the Labour Market in Sri Lanka. International Journal of Innovation and Economic Development, 7(3), 7-17. https://doi.org/10.18775/ijied.1849-7551-7020.2015.73.2001
Baharum, H., Ismail, A., Awang, Z., McKenna, L., Ibrahim, R., Mohamed, Z., y Hassan, N. H. (2023). Validating an Instrument for Measuring Newly Graduated Nurses’ Adaptation. International Journal of Environmental Research and Public Health, 20(4), 2860. https://doi.org/10.3390/ijerph20042860
Bandalos, D. L. y Finney, S. J. (2019). Factor Analysis: Exploratory and Confirmatory. En G.
R. Hancock y R. O. Mueller (Eds.), The Reviewer’s Guide to Quantitative Methods in the Social Sciences (pp. 98-122). New York. Editorial: Routledge. https://doi.org/10.4324/9781315755649-8
Batista-Foguet, J. M., Coenders, G. y Alonso, J. (2004). Análisis factorial confirmatorio. Su utilidad en la validación de cuestionarios relacionados con la salud. Medicina Clínica, 122(S1), 21-27. https://www.elsevier.es/es-revista-medicina-clinica-2-pdf-13057542
Becker, G. S. (1964). Human capital: A Theoretical and Empirical Analysis, with Special Reference to Education (1.a ed., pp. 1-187). New York: National Bureau of Economic Research. http://www.nber.org/books/beck-5
Bentler, P. M. (1990). Comparative fit indexes in structural models. Psychological Bulletin, 107(2), 238-246. https://doi.org/10.1037/0033-2909.107.2.238
Berkman, L. y Macintyre, S. (1997) The measurement of social class in health studies: old measures and new formulations. En Kogevinas, M., Pearce, N., Susser, M. y Boffetta, P. (Eds.), Social Inequalities and Cancer (1.a ed., pp. 51-64). IARC scientific publications. https://publications.iarc.fr/_publications/media/download/3569/ef5ece16d22f088affabfbbacbfd496c923d141a.pdf
Berkowitz, R., Moore, H., Astor, R. A. y Benbenishty, R. (2016). A Research Synthesis of the Associations Between Socioeconomic Background, Inequality, School Climate, and Academic Achievement. Review of Educational Research, 87(2), 425-469. https://doi.org/10.3102/0034654316669821
Bora, N., Chang, Y. H. y Maheswaran, R. (2014). Mobility Patterns and User Dynamics in Racially Segregated Geographies of US Cities. En Kennedy, W. G., Agarwal, N. y Yang, S. J. (Eds.), Social Computing, Behavioral-Cultural Modeling and Prediction. SBP 2014. Lecture Notes in Computer Science (vol. 8393, pp. 11-18). Springer, Cham. https://doi.org/10.1007/978-3-319-05579-4_2
Boterman, W. R. y Musterd, S. (2016). Cocooning urban life: Exposure to diversity in neighbourhoods, workplaces and transport. Cities, 59, 139-147. http://doi.org/10.1016/j.cities.2015.10.018
Bourdieu P. (1986). The forms of capital. En Richardson, J. G. (Ed.), Handbook of theory and research for the sociology of education (pp. 241-258). New York: Greenwood Press. https://home.iitk.ac.in/~amman/soc748/bourdieu_forms_of_capital.pdf
Bollen, K. A. (1989). Structural Equations with Latent Variables. John Wiley & Sons, Inc. https://doi.org/10.1002/9781118619179
Bradley, R. H. y Corwyn, R. F. (2002). Socioeconomic Status and Child Development. Annual Review of Psychology, 53(1), 371-399. https://doi.org/10.1146/annurev.psych.53.100901.135233
Braveman, P. A., Cubbin, C., Egerter, S., Chideya, S., Marchi, K. S., Metzler, M. y Posner, S. (2005). Socioeconomic Status in Health Research: One Size Does Not Fit All. JAMA,
294(22), 2879-2888. https://doi.org/10.1001/jama.294.22.2879
Browne, M. W. y Cudeck, R. (1992). Alternative Ways of Assessing Model Fit. Sociological Methods & Research, 21(2), 230-258. https://doi.org/10.1177/0049124192021002005
Browning, C. R., Calder, C. A., Krivo, L. J., Smith, A. L. y Boettner, B. (2017). Socioeconomic Segregation of Activity Spaces in Urban Neighborhoods: Does Shared Residence Mean Shared Routines? RSF: The Russell Sage Foundation Journal of the Social Sciences, 3(2), 210-231. https://doi.org/10.7758/rsf.2017.3.2.09
Calmet, D. y Capurro, J. M. (2011). El tiempo es dinero: Cálculo del valor social del tiempo en Lima Metropolitana para usuarios de transporte urbano. Revista Estudios Económicos, 20, 73-86. https://www.bcrp.gob.pe/docs/Publicaciones/Revista-Estudios-Economicos/20/ree-20-calmet-capurro.pdf
Campoverde, M. (2024). La Influencia del Entorno Socioeconómico en el Rendimiento Académico. Dominio De Las Ciencias, 10(2), 1488-1498. https://doi.org/10.23857/dc.v10i2.3889
Cao, M., Zhang, Y., Zhang, Y., Li, S. y Hickman, R. (2019). Using different approaches to evaluate individual social equity in transport. En Hickman, R., Mella Lira, B., Givoni, M. y Geurs, K. (Eds.), A Companion to Transport, Space and Equity, Edward Elgar Publishing (pp. 209-228). https://doi.org/10.4337/978178 8119825.00024
Caro, D. (2002). Estimación del nivel socioeconómico de las familias: Propuesta metodológica para la Evaluación Nacional de Rendimiento del 2001. https://www.researchgate.net/publication/293817504_Estimacion_del_nivel_socioeconomico_de_las_familias_Propuesta_metodologica_para_la_Evaluacion_Nacional_de_Rendimiento_del_2001
Caro, D. y Cortés, D. (2012). Measuring family socioeconomic status: An illustration using data from PIRLS 2006. En von D., M y Hastedt, D. (Eds.), IERI Monograph Series: Issues and Methodologies in Large-Scale Assessments (Vol. 5, pp. 9-33). https://ierinstitute.org/fileadmin/Documents/IERI_Monograph/Volume_5/IERI_Monograph_Volume_05.pdf
Caro, D., McDonald, J. T. y Willms, J. D. (2009). Socio-economic status and academic achievement trajectories from childhood to adolescence. Canadian Journal of Education, 32(3), 558-590. https://eric.ed.gov/?id=E J859263
Chapin, F. S. (1928). A quantitative scale for rating the home and social environment of middle class families in an urban community: a first approximation to the measurement of socio-economic status. Journal of Educational Psychology, 19(2), 99-111. https://doi.org/10.1037/h0074500
Cheung, G. W. y Wang, C. (2017). Current approaches for assessing convergent and discriminant validity with SEM: issues and solutions. En Academy of management proceedings (vol. 2017, No. 1, p. 12706). Briarcliff Manor, NY 10510: Academy of Management. https://doi.org/10.5465/ambpp.2017.12706abstract
Çiftçi, Ş. K. y Cin, F. M. (2017). The effect of socioeconomic status on students’ achievement. En E. Karadağ (Ed.), The factors effecting student achievement (pp. 171-181). Springer, Cham. https://doi.org/10.1007/ 978-3-319-56083-0_10
Coleman, J. S. (1988). Social Capital in the Creation of Human Capital. American Journal of Sociology, 94, S95-S120. https://doi.org/10.1086/228943
Cowan, C. D., Hauser, R. M., Kominski, R. A., Levin, H. M., Lucas, S. R., Morgan, S. L., Spencer, M. B. y Chapman, C. (2012). Improving the measurement of socioeconomic status for the National Assessment of Educational Progress: A theoretical foundation. Recommendations to the National Center for Education Statistics. National Center for Education Statistics (NCSE). Institute of Education Sciences (IES), Washington, D.C. https://nces.ed.gov/nationsreportcard/pdf/researchcenter/Socioeconomic_ Factors.pdf.
Cuellar, E. J., Guerrero, S. y López, D. (2016). Propuesta para la construcción de un índice socioeconómico para los estudiantes que presentan las pruebas Saber Pro. Comunicaciones en Estadística, 9(1), 93-106. https://dialnet.unirioja.es/servlet/articulo?codigo=7396912
Desu, S (2015). Untangling the effects of residential segregation on individual mobility [Tesis doctoral, Massachusetts Institute of Technology]. MIT Digital Repository. http://hdl.handle.net/1721.1/106957
Dickinson, E. R. y Adelson, J. L. (2014). Exploring the Limitations of Measures of Students’ Socioeconomic Status (SES). Practical Assessment, Research & Evaluation, 19(1), 1-14. http://files.eric.ed.gov/fulltext/EJ1031260.pdf
Diemer, M. A., Mistry, R. S., Wadsworth, M. E., López, I. y Reimers, F. (2012). Best Practices in Conceptualizing and Measuring Social Class in Psychological Research. Analyses of Social Issues and Public Policy, 13(1), 77-113. https://doi.org/10.1111/asap.12001
Dong, X., Morales, A.J., Jahani, E., Moro, E., Lepri, B., Bozkaya, B., Sarraute, C., Bar-Yam, Y. y Pentland, A. (2020). Segregated interactions in urban and online space. EPJ Data Science, 9(20), 1-22. https://doi.org/10.1140/epjds/s13688-020-00238-7
Ensminger, M. E., Forrest, C. B., Riley, A. W., Kang, M., Green, B. F., Starfield, B. y Ryan, S. A. (2000). The Validity of Measures of Socioeconomic Status of Adolescents. Journal of Adolescent Research, 15(3), 392-419. https://doi.org/10.1177/0743558400153005
Ensminger, M. E. y Fothergill, K. E. (2014). A decade of measuring SES: What it tells us and where to go from here. En Socioeconomic Status, Parenting, and Child Development (pp. 13-27). Taylor and Francis. https://doi.org/10.4324/9781410607027-9
Entwisle, D. R. y Astone, N. M. (1994). Some Practical Guidelines for Measuring Youth’s Race/Ethnicity and Socioeconomic Status. Child Development, 65(6), 1521-1540. https://doi.org/10.2307/1131278
Erdem, C. y Kaya, M. (2021). Socioeconomic status and wellbeing as predictors of students’ academic achievement: evidence from a developing country. Journal of Psychologists and Counsellors in Schools, 1-19. https://doi.org/10.1017/jgc.2021.10
Feres, J. C. y Mancero, X. (2001). El método de las necesidades básicas insatisfechas (NBI) y sus aplicaciones en América Latina. Serie: Estudios estadísticos. CEPAL, Santiago de Chile, Chile. https://repositorio.cepal.org/server/api/core/bitstreams/da8d48c5-0807-4bd1-b330-c0a9e1566e02/content
Ferrando, P. J. y Anguiano-Carrasco, C. (2010). El análisis factorial como técnica de investigación en psicología. Papeles del Psicólogo, 31(1), 18-33. https://www.redalyc.org/articulo.oa?id=77812441003
Ferrão, M. (2009). Sensibilidad de las especificaciones de los modelos de valor añadido: Midiendo el estatus socioeconómico. Revista de educación, 348, 137-152. https://redined.educacion.gob.es/xmlui/bitstream/handle/11162/72342/00820093000018.pdf?sequence=1&isAllowed=y
Fornell, C. y Larcker, D. F. (1981). Evaluating Structural Equation Models with Unobservable Variables and Measurement Error. Journal or Marketing Research, 18(1), 39-50.
https://doi.org/10.2307/3151312
Fotso, J.-C. y Kuate-Defo, B. (2005). Measuring Socioeconomic Status in Health Research in Developing Countries: Should We Be Focusing on Households, Communities or Both? Social Indicators Research, 72(2), 189-237. https://doi.org/10.1007/s11205-004-5579-8
Fujihara, S. (2020). Socio-Economic Standing and Social Status in Contemporary Japan: Scale Constructions and Their Applications. European Sociological Review, 36(4), 548-561. https://doi.org/10.1093/esr/jcaa010
Gagné, T. y Ghenadenik, A. E. (2017). Rethinking the relationship between socioeconomic status and health: Challenging how socioeconomic status is currently used in health inequality research. Scandinavian Journal of Public Health, 46(1), 53-56. https://doi.org/10.1177/1403494817744987
Garrett, M. y Taylor, B. (1999). Reconsidering Social Equity in Public Transit. Berkeley Planning Journal, 13(1), 6-27. https://doi.org/10.5070/bp313113028
George, D. y Mallery, P. (2010). SPSS for Windows step by step: A simple guide and reference, 17.0 update (10.a ed.). Allyn y Bacon. https://lib.ugent.be/catalog/rug01:001424067
Gill, J. (2011). Medición del nivel socioeconómico familiar en el alumnado de Educación Primaria. Revista de Educación, 362, 298-322. https://doi.org/10.4438/1988-592X-RE-2011-362-162
Gobierno Provincial de Chiclayo (GPCH, 2003). Ordenanza Municipal No 021-A-2003 GPCH. Municipalidad Provincial de Chiclayo (MPCH). https://www.munichiclayo.gob.pe/index.php?cp=2175&tipo=mpu&op=2
Gottfried, A. W. (1985). Measures of Socioeconomic Status in Child Development Research: Data and Recommendations. Merrill-Palmer Quarterly, 31(1), 85-92. http://www.jstor.org/stable/23086136
Hadiuzzman, M., Das, T., Hasnat, M. M., Hossain, S. y Rafee Musabbir, S. (2017). Structural equation modeling of user satisfaction of bus transit service quality based on stated preferences and latent variables. Transportation Planning and Technology, 40(3), 257-277. https://doi.org/10.1080/03081060.2017.1283155
Haer, J. L. (1957). Predictive Utility of Five Indices of Social Stratification. American Sociological Review, 22(5), 541-546. https://doi.org/10.2307/2089478
Haretche, C. (2011). Elaboración de un Índice de Estatus Socioeconómico aplicando el modelo de Rasch en muestras representativas de escuelas en tres regiones de América Latina. Revista Latinoamericana de Estudios Educativos (México), 41(3-4), 15-43. https://www.redalyc.org/articulo.oa?id=27022351002
Haug, M. R. (1977). Measurement in Social Stratification. Annual Review of Sociology, 3(1), 51-77. http://www.jstor.org/stable/2945930
Hauser, R. M. (1994). Measuring Socioeconomic Status in Studies of Child Development. Child Development, 65(6), 1541-1545. https://doi.org/10.2307/1131279
Herrero, J. (2010). El Análisis Factorial Confirmatorio en el estudio de la Estructura y Estabilidad de los Instrumentos de Evaluación: Un ejemplo con el Cuestionario de Autoestima CA-14. Psychosocial Intervention, 19(3), 289-300. https://doi.org/10.5093/in2010v19n3a9
Hilman, R. M., Iñiguez, G. y Karsai, M. (2022). Socioeconomic biases in urban mixing patterns
of US metropolitan areas. EPJ data science, 11(1), 1-32. https://doi.org/10.1140/epjds/s13688-022-00341-x
Iceland, J., Weinberg, D. H. y Steinmetz, E. (2002). Racial and ethnic residential segregation in the United States 1980-2000 (vol. 8, No. 3). U. S. Census Bureau, Washington, D. C. 20233-8500. https://corpora.tika.apache.org/base/docs/govdocs1/207/207896.pdf
Incio, D. E. (2014). Evaluación del congestionamiento vehicular en la ciudad de Chiclayo y propuestas de mejora [Tesis de pregrado, Universidad Nacional Pedro Ruiz Gallo]. Repositorio Institucional UNPRG. https://hdl.handle.net/20.500.12893/414
Instituto Nacional de Estadística e Informática (INEI, 2018). Censos Nacionales 2017: Resultados Definitivos del departamento de Lambayeque. https://www.inei.gob.pe/media/MenuRecursivo/publicaciones_digitales/Est/Lib1560/
Instituto Nacional de Estadística e Informática (INEI, 2019). Encuesta Nacional de Hogares (ENAHO) sobre condiciones de vida y pobreza, enero-diciembre de 2019: Metodología actualizada [Base de datos]. https://proyectos.inei.gob.pe/microdatos/
Kaiser, H. F. (1970). A second generation little jiffy. Psychometrika, 35(4), 401-415. https://doi.org/10.1007/BF02291817
Kline, R. B. (2016). Principles and practice of structural equation modeling (4.a ed.). New York: Guilford Press. https://dl.icdst.org/pdfs/files4/befc0f8521c770249dd18726a917cf90.pdf
Korous, K. M., Bradley, R. H., Luthar, S. S., Li, L., Levy, R., Cahill, K. M. y Rogers, C. R. (2022). Socioeconomic status and depressive symptoms: An individual-participant data meta-analysis on range restriction and measurement in the United States. Journal of affective disorders, 314, 50-58. https://doi.org/10.1016/j.jad.2022.06.090
Lavado, P., Yamada, G. y Martínez, J. (2014). ¿Una promesa incumplida? La calidad de la educación superior universitaria y el subempleo profesional en el Perú. Documento de trabajo 2014-021. Banco Central de Reserva del Perú, 1-72. https://www.bcrp.gob.pe/docs/Publicaciones/Documentos-de-Trabajo/2014/documento-de-trabajo-21-2014.pdf
Lee, S. Y. y Jennrich, R. I. (1979). A study of algorithms for covariance structure analysis with specific comparisons using factor analysis. Psychometrika, 44(1), 99-113. https://doi.org/10.1007/BF02293789
León, J. y Collahua, Y. (2016). El efecto del nivel socioeconómico en el rendimiento de los estudiantes peruanos: un balance de los últimos 15 años. En Cueto, S. (Ed.), Investigación para el desarrollo en el Perú: Once balances (vol. 1, pp. 109-162). Lima: Grupo de Análisis para el Desarrollo (GRADE). https://www.grade.org.pe/wp-content/uploads/nserendimiento_JL_35.pdf
Liao, Y., Gil, J., Yeh, S., Pereira, R. H. y Alessandretti, L. (2024). Socio-spatial segregation and human mobility: A review of empirical evidence. arXiv preprint arXiv:2403.06641. https://doi.org/10.48550/arXiv.2403.06641
Liu, J., Peng, P., Zhao, B. y Luo, L. (2022). Socioeconomic Status and Academic Achievement in Primary and Secondary Education: a Meta-analytic Review. Educational Psychology Review, 34(4), 2867-2896. https://doi.org/10.1007/s10648-022-09689-y
Lloret-Segura, S., Ferreres-Traver, A., Hernández-Baeza, A. y Tomás-Marco, I. (2014). El
análisis factorial exploratorio de los ítems: una guía práctica, revisada y actualizada. Anales de Psicología, 30(3), 1151-1169. https://doi.org/10.6018/analesps.30.3.199361
Long, K. y Renbarger, R. (2023). Persistence of Poverty: How Measures of Socioeconomic Status Have Changed Over Time. Educational Researcher, 52(3), 144-154. https://doi.org/10.3102/0013189X221141409
López, M. C., Loaiza, A. G. y Henostroza, F. (2022). Efectos del nivel socioeconómico sobre el rendimiento académico en primaria: Una revisión sistemática sobre el rol mediador de las funciones ejecutivas. Revista de Investigación en Psicología, 25(2), 141-160. http://dx.doi.org/10.15381/rinvp.v25i2.22883
López-Aguado, M. y Gutiérrez-Provecho, L. (2019). Cómo realizar e interpretar un análisis factorial exploratorio utilizando SPSS. REIRE Revista d’Innovació i Recerca en Educació, 12(2), 1-14. http://doi.org/10.1344/reire2019.12.227057
Malecki, C. K. y Demaray, M. K. (2006). Social support as a buffer in the relationship between socioeconomic status and academic performance. School Psychology Quarterly, 21(4), 375-395. https://doi.org/10.1037/h0084129
Manayay, D. T. (2020). El empleo informal en el Perú: Una breve caracterización 2007-2018. Pensamiento Crítico, 25(1), 51-75. http://dx.doi.org/10.15381/pc.v25i1.18477
Marston, S. A. (2000). The social construction of scale. Progress in Human Geography, 24(2), 219-242. https://doi.org/10.1191/030913200674086272
Marx K. y Engels F. (1964). The communist manifesto. New York: Simon y Schuster.
May, H. (2006). A Multilevel Bayesian Item Response Theory Method for Scaling Socioeconomic Status in International Studies of Education. Journal of Educational and Behavioral Statistics, 31(1), 63-79. https://doi.org/10.3102/10769986031001063
McLeod, J. D. y Nonnemaker, J. M. (1999). Social Stratification and Inequality. En C. S. Aneshensel y J. C. Phelan (Eds.), Handbook of the Sociology of Mental Health (pp. 321-344). Springer, Boston, MA. https://doi.org/10.1007/0-387-36223-1_16
McPherson, M., Smith-Lovin, L. y Cook, J. M. (2001). Birds of a Feather: Homophily in Social Networks. Annual Review of Sociology, 27(1), 415-444. http://doi.org/10.1146/annurev.soc.27.1.415
Ministerio de Educación. (MINEDU, 2018). Desafíos en la medición y el análisis del estatus socioeconómico de los estudiantes peruanos (1.a ed.). Lima: Oficina de Medición de la Calidad de los Aprendizajes. Perú. https://hdl.handle.net/20.500.12799/5862
Ministerio del Trabajo y Promoción de Empleo (MTPE, 2020). Reporte del empleo formal en la región Lambayeque a diciembre 2020 (Sede web, pp. 1-6). Dirección de Supervisión y Evaluación de la Dirección General de Políticas para la Promoción de la Formalización Laboral e Inspección del Trabajo. Lima, Perú: MTPE. https://cdn.www.gob.pe/uploads/document/file/1744028/14.%20Lambayeque.pdf
Morales, A. J., Dong, X., Bar-Yam, Y. y Pentland, A. (2019). Segregation and polarization in urban areas. Royal Society Open Science, 6(10), 1-15, 190573. http://dx.doi.org/10.1098/rsos.190573
Morales, K., Flores, M. S. y Salazar Méndez, Y. S. (2021). Analysis of Principal Nonlinear Components for the Construction of a Socioeconomic Stratification Index in Ecuador. Revista Desarrollo y Sociedad, (88), 43-82. https://doi.org/10.13043/DYS.88.2
Moro, E., Calacci, D., Dong, X. y Pentland, A. (2021). Mobility patterns are associated with experienced income segregation in large US cities. Nature Communications, 12(1), 1-10. https://doi.org/10.1038/s41467-021-24899-8
Mueller, C. W. y Parcel, T. L. (1981). Measures of Socioeconomic Status: Alternatives and Recommendations. Child Development, 52(1), 13-30. https://doi.org/10.2307/1129211
Muthén, B. y Kaplan, D. (1985). A comparison of some methodologies for the factor analysis of non-normal Likert variables. British Journal of Mathematical and Statistical Psychology, 38(2), 171-189. https://doi.org/10.1111/j.2044-8317.1985.tb00832.x
Muthén, B. y Kaplan, D. (1992). A comparison of some methodologies for the factor analysis of non-normal Likert variables: A note on the size of the model. British Journal of Mathematical and Statistical Psychology, 45(1), 19-30. https://doi.org/10.1111/j.2044-8317.1992.tb00975.x
Naushad, R. B. (2022). Differential effects of socio-economic status and family environment of adolescents on their emotional intelligence, academic stress and academic achievement. IJERI: International Journal of Educational Research and Innovation, (17), 101-120. https://doi.org/10.46661/ijeri.5148
Netto, V. M., Soares, M. P. y Paschoalino, R. (2015). Segregated Networks in the City. International Journal of Urban and Regional Research, 39(6), 1084-1102. https://doi.org/10.1111/1468-2427.12346
Oakes, J. M. y Rossi, P. H. (2003). The measurement of SES in health research: current practice and steps toward a new approach. Social Science & Medicine, 56(4), 769-784. https://doi.org/10.1016/s0277-9536(02)000 73-4
Okoye, N. S. y Okecha, R. E. (2008). The Interaction of Logical Reasoning Ability and Socio-Economic Status on Achievement in Genetics among Secondary School Students in Nigeria. College Student Journal, 42(2), 617-624. https://eric.ed.gov/?id=EJ816956
Paasi, A. (2004). Place and region: looking through the prism of scale. Progress in Human Geography, 28(4), 536-546. https://doi.org/10.1191/0309132504ph502pr
Parsons, T. (1940). An analytical approach to the theory of social stratification. American Journal of Sociology, 45(6), 841-862. https://doi.org/10.1086/218489
Peña, D. (2013). Análisis de datos multivariantes (2.a ed.). McGraw-Hill/Interamericana de España, S. L. https://elibro.net/es/ereader/bibsipan/50267
Raudenbush, S. W. y Willms, J. D. (1995). The Estimation of School Effects. Journal of Educational and Behavioral Statistics, 20(4), 307-335. https://doi.org/10.3102/10769986020004307
Raykov, T. y Marcoulides, G. A. (2006). A First Course in Structural Equation Modeling (2.a ed.). Mahwah, New Jersey: Lawrence Erlbaum Associates, Inc., Publishers. https://api.pageplace.de/preview/DT0400.9781135600761_A23805293/preview-9781135600761_A23805293.pdf
Rodríguez, L. J., Maza, O. M., Macías, J. C. y Ortiz, D. A. (2020). Analysis of inequality via social stratification. Entreciencias: Diálogos en la Sociedad del Conocimiento, 8(22). https://doi.org/10.22201/enesl.2007806 4e.2020.2276859e22.76859
Rodríguez, S. y Cabrera-Barona, P. (2024). Segregación espacial y condiciones sociodemográficas de la población de Quito, Ecuador. EURE (Santiago), 50(150), 1-18.
http://dx.doi.org/10.7764/eure.50.150.05
Rodríguez, V. y Espinoza, B. (2015). Generación de un índice socioeconómico para los productores de plátano de la reserva indígena Rey Curré. Revista e-Agronegocios, 1(2), 1-17. https://revistas.tec.ac.cr/index.php/eagronegocios/article/view/3662/3284
Rumberger, R. W. y Palardy, G. J. (2005). Does segregation still matter? The impact of student composition on academic achievement in high school. Teachers college record, 107(9), 1999-2045. https://doi.org/10.1111/j.1467-9620.2005.00583.x
Santoso, R. P., Sahadewo, G. A., Sugiyanto, C. y Setiastuti, S. U. (2022). Informal and Formal Wage Differences Based on Cohorts in Indonesia. Economies, 10(12), 317, 1-13. https://doi.org/10.3390/economies10120317
Siesquén Díaz, J. K. y Cabrejos Moreno, L. S. (2024). Tráfico interprovincial y el costo de oportunidad al transportarse por la avenida Francisco Bolognesi en Chiclayo durante el 2019 [Tesis de pregrado, Universidad Nacional Pedro Ruiz Gallo]. Repositorio Institucional UNPRG. https://hdl.handle.net/20.500.12893/12428
Sirin, S. R. (2005). Socioeconomic Status and Academic Achievement: A Meta-Analytic Review of Research. Review of Educational Research, 75(3), 417-453. https://doi.org/10.3102/00346543075003417
Srivastava, R. (2019). Emerging Dynamics of Labour Market Inequality in India: Migration, Informality, Segmentation and Social Discrimination. The Indian Journal of Labour Economics, 62, 147-171. https://doi.org/10.1007/s41027-019-00178-5
Taeuber, K. E. y Taeuber, A. F. (2008). Residential segregation and neighborhood change. Transaction Publishers, London.
Tang, Y. (2017). Social Class Index: A New Measurement for Gender Social Stratification. Sociology and Anthropology, 5(5), 388-398. https://doi.org/10.13189/sa.2017.050502
Toma, J. y Rubio, J. L. (2017). Estadística aplicada: Primera parte (2.a ed.). Universidad del Pacífico, Centro de Investigación.
van Ewijk, R. y Sleegers, P. (2010). The effect of peer socioeconomic status on student achievement: A meta-analysis. Educational Research Review, 5(2), 134-150. https://doi.org/10.1016/j.edurev.2010.02.001
Velez, E., Schiefelbein, E. y Valenzuela, J. (1994). Factores que Afectan el Rendimiento Académico en la Educación Primaria: Revisión de la Literatura de América Latina y El Caribe. https://repositorio.minedu.gob.pe/handle/20.500.12799/4317
Vera, O. E. y Vera, F. M. (2013). Evaluación del nivel socioeconómico: Presentación de una escala adaptada en una población de Lambayeque. Revista del Cuerpo Médico Hospital Nacional Almanzor Aguinaga Asenjo, 6(1), 41-45. https://dialnet.unirioja.es/servlet/articulo?codigo=4262712
Villatoro, P. (Comp.). (2017). Indicadores no monetarios de pobreza: avances y desafíos para su medición. Comisión Económica para América Latina y el Caribe (CEPAL), División de Estadísticas. https://repositorio.cepal.org/server/api/core/bitstreams/3694ebea-6a10-4db6-8fe3-d69e2914b5df/content
Wang, Q., Phillips, N. E., Small, M. L. y Sampson, R. J. (2018). Urban mobility and neighborhood isolation in America’s 50 largest cities. Proceedings of the National Academy of Sciences, 115(30), 7735-7740. http://doi.org/10.1073/pnas.1802537115
Ware, J. K. (2017). Property Value as a Proxy of Socioeconomic Status in Education. Education and Urban Society, 51(1), 99-119. https://doi.org/10.1177/0013124517714850
Weber M. (1946). Class, Status, Party. En H. H. Gerth y C. W. Mills (Eds.), From Max Weber: Essays in sociology (pp. 180-195). New York: Oxford University Press. (Original work published 1920). http://www.soc.duke.edu/~jmoody77/TheoryNotes/Weber_CSP.htm
Weiser, D. A. y Riggio, H. R. (2010). Family background and academic achievement: Does self-efficacy mediate outcomes? Social Psychology of Education, 13(3), 367-383. https://doi.org/10.1007/s11218-010-9115-1
White, K. R. (1982). The Relation Between Socioeconomic Status and Academic Achievement. Psychological Bulletin, 91(3), 461-481. https://doi.org/10.1037/0033-2909.91.3.461
Wicki, B. (2022). The main task of urban public health: narrowing the health gap between the poor and the rich. International Journal of Public Health, 67: 1605084. https://doi.org/10.3389/ijph.2022.1605084
Willms, J. D. (2002). Standards of Care: Investments to Improve Children’s Education Outcomes in Latin America. En M. E. Young (Ed.), From Early Child Development to Human Development: Investing in Our Children’s Future. Part II: Measuring the Early Opportunity Gap (cap. 4, pp. 81-122). Washington, D. C.: The World Bank. https://documents1.worldbank.org/curated/en/247161468336079362/pdf/239490PUB0Repl0top0150500same0info0.pdf
Wulandari, R. D., Susilo, S. y Satria, D. (2018). Income Inequality between Formal-Informal Employees Based on Education Group. Economics and Finance in Indonesia, 64(1), 25-42. https://typeset.io/pdf/income-inequality-between-formal-informal-employees-based-on-4nw6aswou8.pdf
Yamada, G., Lavado, P. y Oviedo, N. (2017). Rendimiento laboral de la educación superior: evidencia a partir de Ponte en Carrera. En Yamada, G. y Lavado, P. (Eds.), Educación superior y empleo en el Perú: Una brecha persistente (1.a ed., pp. 37-70). Universidad del Pacífico.
Yip, N. M., Forrest, R. y Xian, S. (2016). Exploring segregation and mobilities: Application of an activity tracking app on mobile phone. Cities, 59, 156-163. http://dx.doi.org/10.1016/j.cities.2016.02.003
Zhou, X., y Wodtke, G. T. (2019). Income Stratification among Occupational Classes in the United States. Social Forces, 97(3), 945-972. https://doi.org/10.1093/sf/soy074